R for Plotting
Overview
Teaching: 150 min
Exercises: 20 minQuestions
What are R and R Studio?
How do I write code in R?
What is the tidyverse?
How do I read data into R?
What are geometries and aesthetics?
How can I use R to create and save professional data visualizations?
Objectives
To become oriented with R and R Studio.
To create plots with both discrete and continuous variables.
To understand mapping and layering using
ggplot2.To be able to modify a plot’s color, theme, and axis labels.
To be able to save plots to a local directory.
Contents
- Introduction to R and RStudio
- Introduction to the tidyverse
- Loading and reviewing data
- Understanding commands
- Creating our first plot
- Plotting for data exploration
- Glossary of terms
Bonus: why learn to program?
Share why you’re interested in learning how to code.
Solution:
There are lots of different reasons, including to perform data analysis and generate figures. I’m sure you have more specific reasons for why you’d like to learn! Add a
Introduction to R and RStudio
Over this workshop, we will be working with data from the Schmidt Lab, here at Cornell. They collected microbial samples across Lake Ontario on the US EPA RV Lake Guardian. They want to understand how environmental conditions in the lake (things like temperature and nutrients) affect the abundance of different bacterial taxa.
To test this hypothesis, we’ll need two things: data and a platform to analyze the data.
You already downloaded the data. But what platform will we use to analyze the data? We have many options!
We could try to use a spreadsheet program like Microsoft Excel or Google sheets that have limited access, less flexibility, and don’t easily allow for things that are critical to “reproducible” research, like easily sharing the steps used to explore and make changes to the original data.
Instead, we’ll use a programming language to test our hypothesis. Today we will use R, but we could have also used Python for the same reasons we chose R (and we teach workshops for both languages). Both R and Python are freely available, the instructions you use to do the analysis are easily shared, and by using reproducible practices, it’s straightforward to add more data or to change settings like colors or the size of a plotting symbol.
But why R and not Python?
There’s no great reason. Although there are subtle differences between the languages, it’s ultimately a matter of personal preference. Both are powerful and popular languages that have very well developed and welcoming communities of scientists that use them. As you learn more about R, you may find things that are annoying in R that aren’t so annoying in Python; the same could be said of learning Python. If the community you work in uses R, then you’re in the right place.
To run R, all you really need is the R program, which is available for computers running the Windows, Mac OS X, or Linux operating systems. You downloaded R while getting set up for this workshop.
To make your life in R easier, there is a great (and free!) program called RStudio that you also downloaded and used during set up. As we work today, we’ll use features that are available in RStudio for writing and running code, managing projects, installing packages, getting help, and much more. It is important to remember that R and RStudio are different, but complementary programs. You need R to use RStudio.
Bonus Exercise: Can you think of a reason you might not want to use RStudio?
Solution:
On some high-performance computer systems (e.g. Amazon Web Services) you typically can’t get a display like RStudio to open. In that case, you’ll write your code in R Scripts, and then run those scripts from the command line.
To get started, we’ll spend a little time getting familiar with the RStudio environment and setting it up to suit your tastes. When you start RStudio, you’ll have three panels.
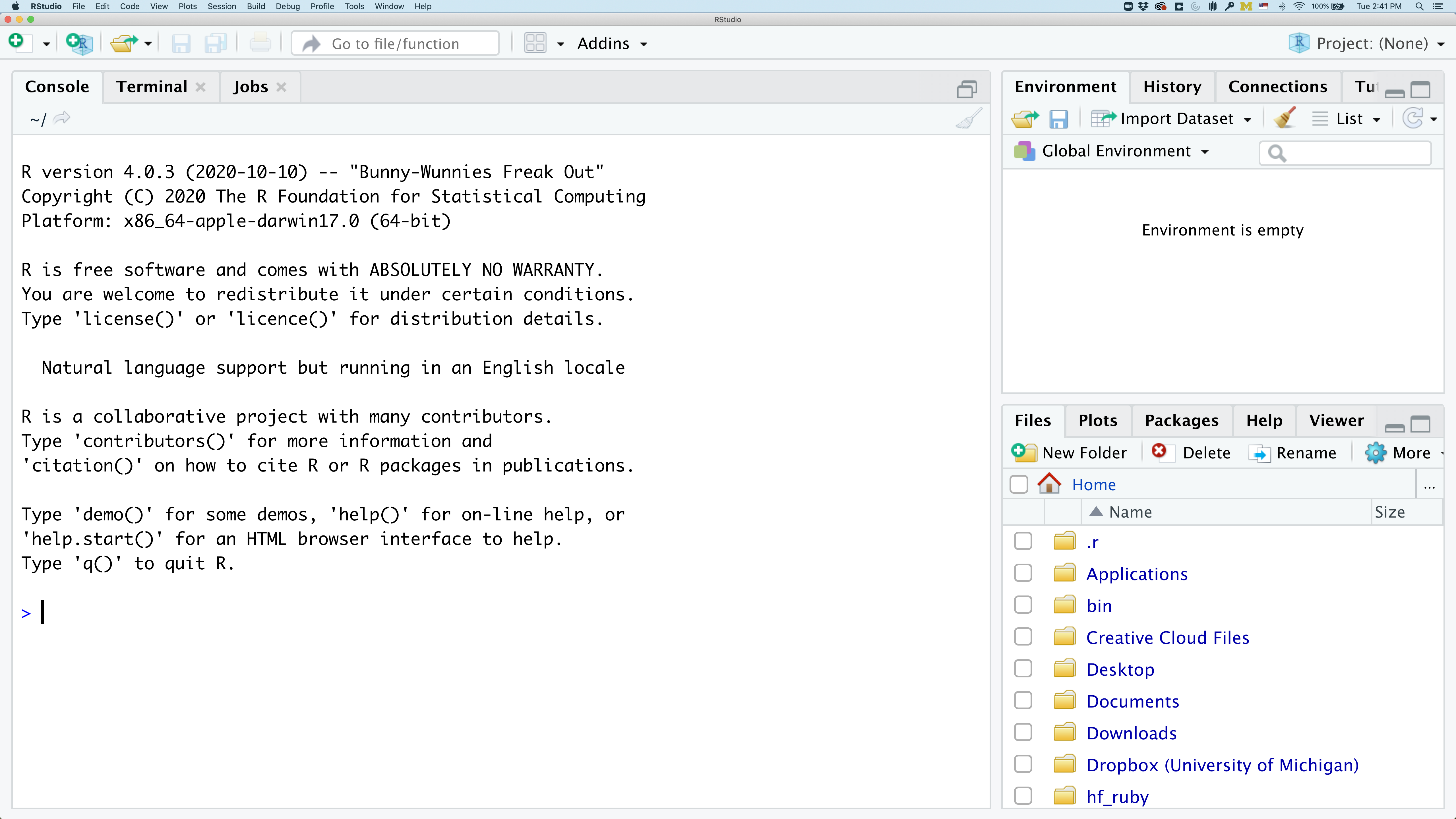
On the left you’ll have a panel with three tabs - Console, Terminal, and Jobs. The Console tab is what running R from the command line looks like. This is where you can enter R code. Try typing in 2+2 at the prompt (>). In the upper right panel are tabs indicating the Environment, History, and a few other things. If you click on the History tab, you’ll see the command you ran at the R prompt.
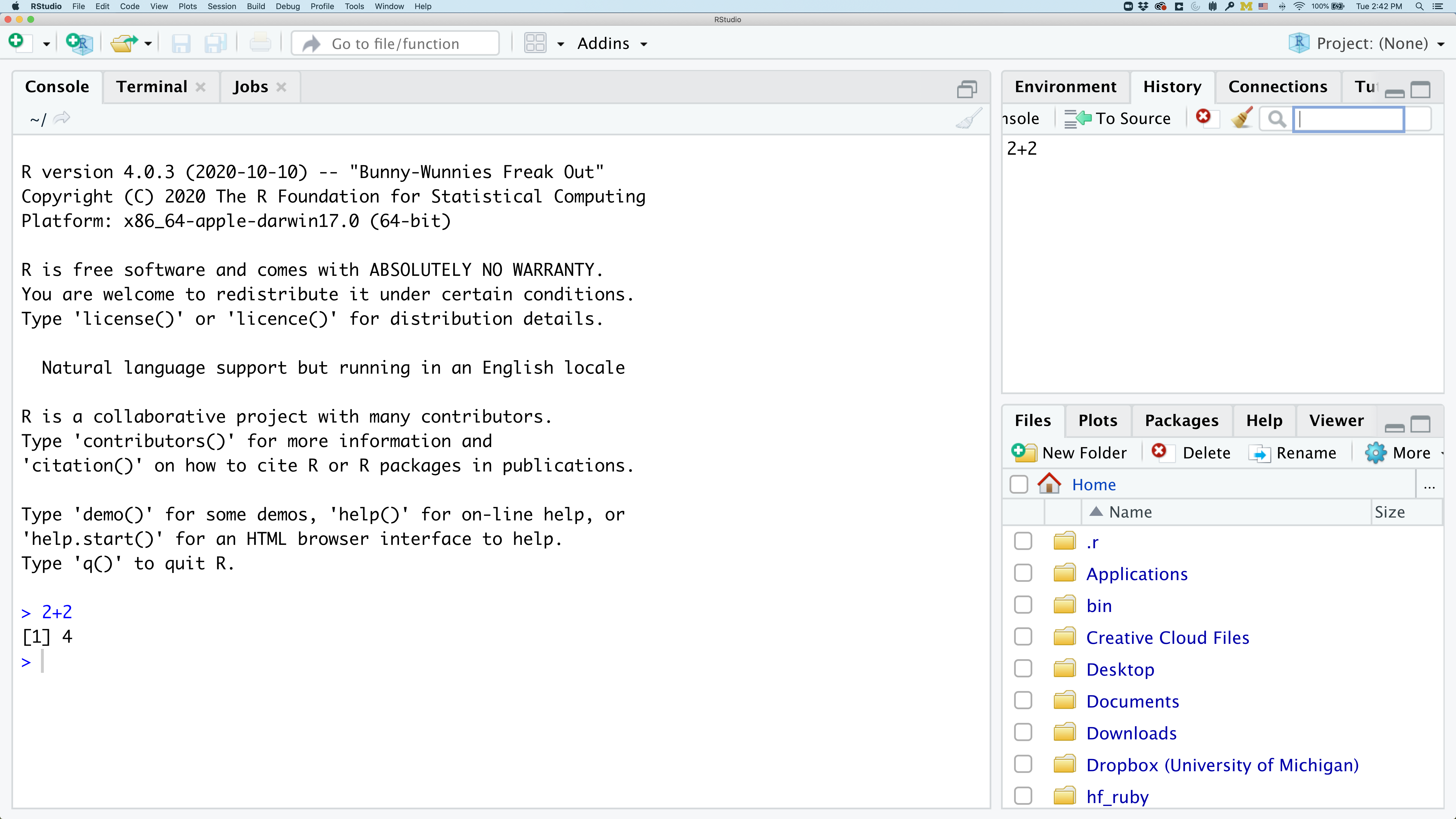
In the lower right panel are tabs for Files, Plots, Packages, Help, and Viewer.
We’ll spend more time in each of these tabs as we go through the workshop, so we won’t spend a lot of time discussing them now.
You might want to alter the appearance of your RStudio window. The default appearance has a white background with black text. If you go to the Tools menu at the top of your screen, you’ll see a “Global options” menu at the bottom of the drop down; select that.
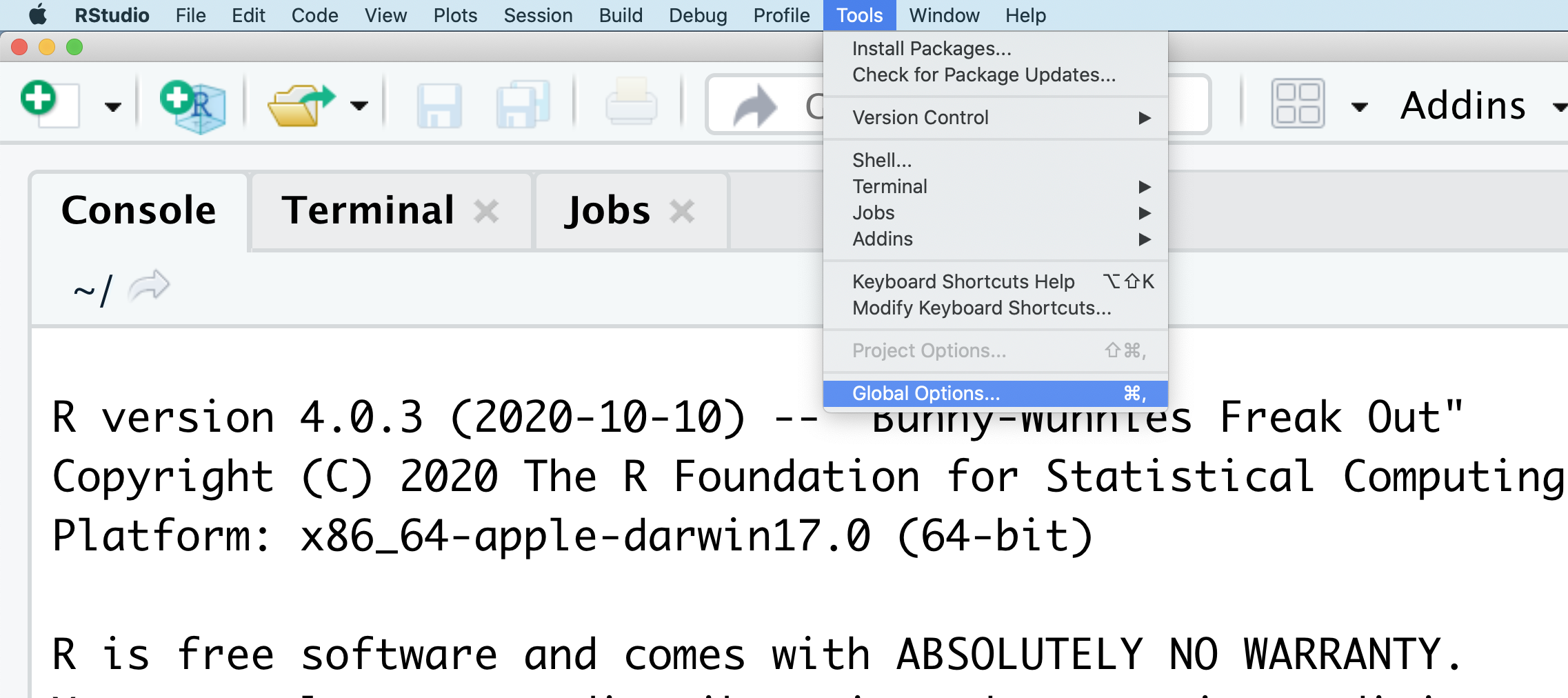
From there you will see the ability to alter numerous things about RStudio. Under the Appearances tab you can select the theme you like most. As you can see there’s a lot in Global options that you can set to improve your experience in RStudio. Most of these settings are a matter of personal preference.
However, you can update settings to help you to insure the reproducibility of your code. In the General tab, none of the selectors in the R Sessions, Workspace, and History should be selected. In addition, the toggle next to “Save workspace to .RData on exit” should be set to never. These setting will help ensure that things you worked on previously don’t carry over between sessions.
Let’s get going on our analysis!
One of the helpful features in RStudio is the ability to create a project. A project is a special directory that contains all of the code and data that you will need to run an analysis.
At the top of your screen you’ll see the “File” menu. Select that menu and then the menu for “New Project…”.
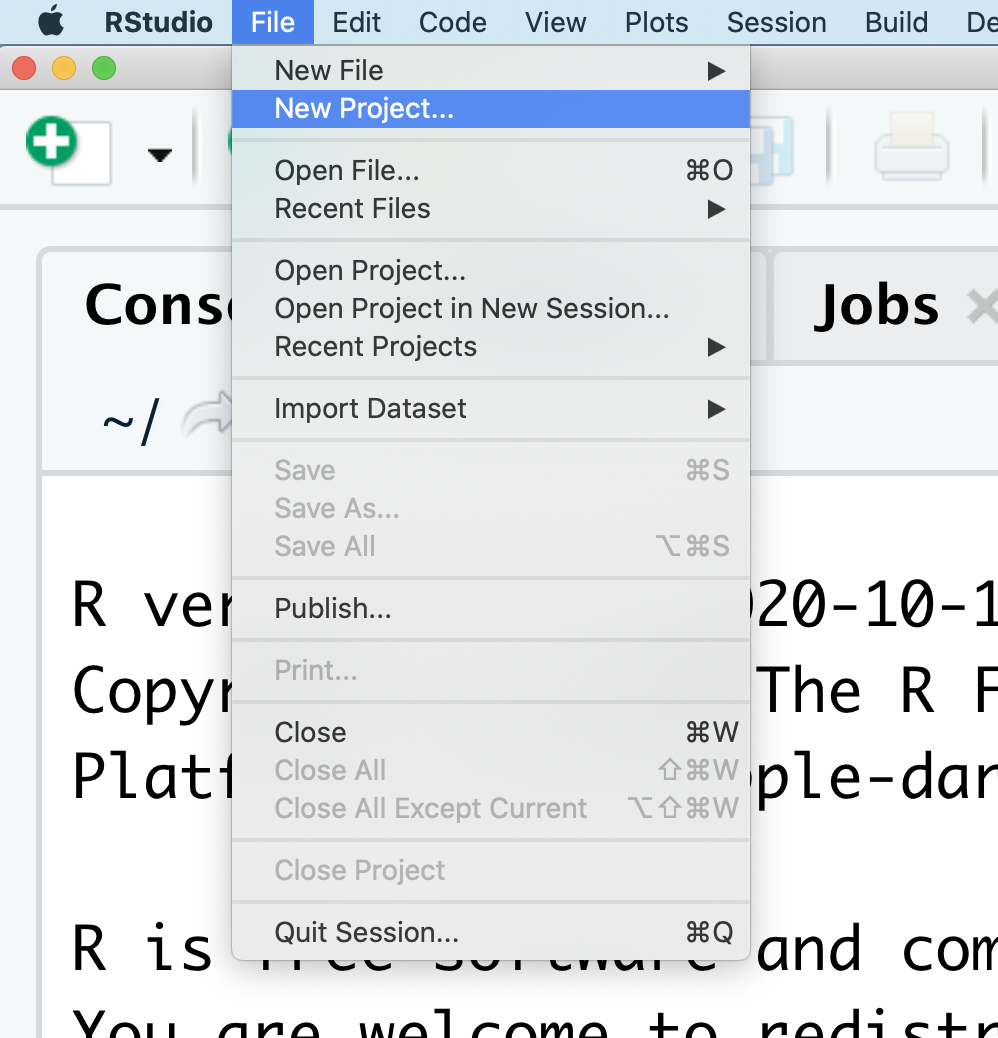
When the smaller window opens, select “Existing Directory” and then the “Browse” button in the next window.
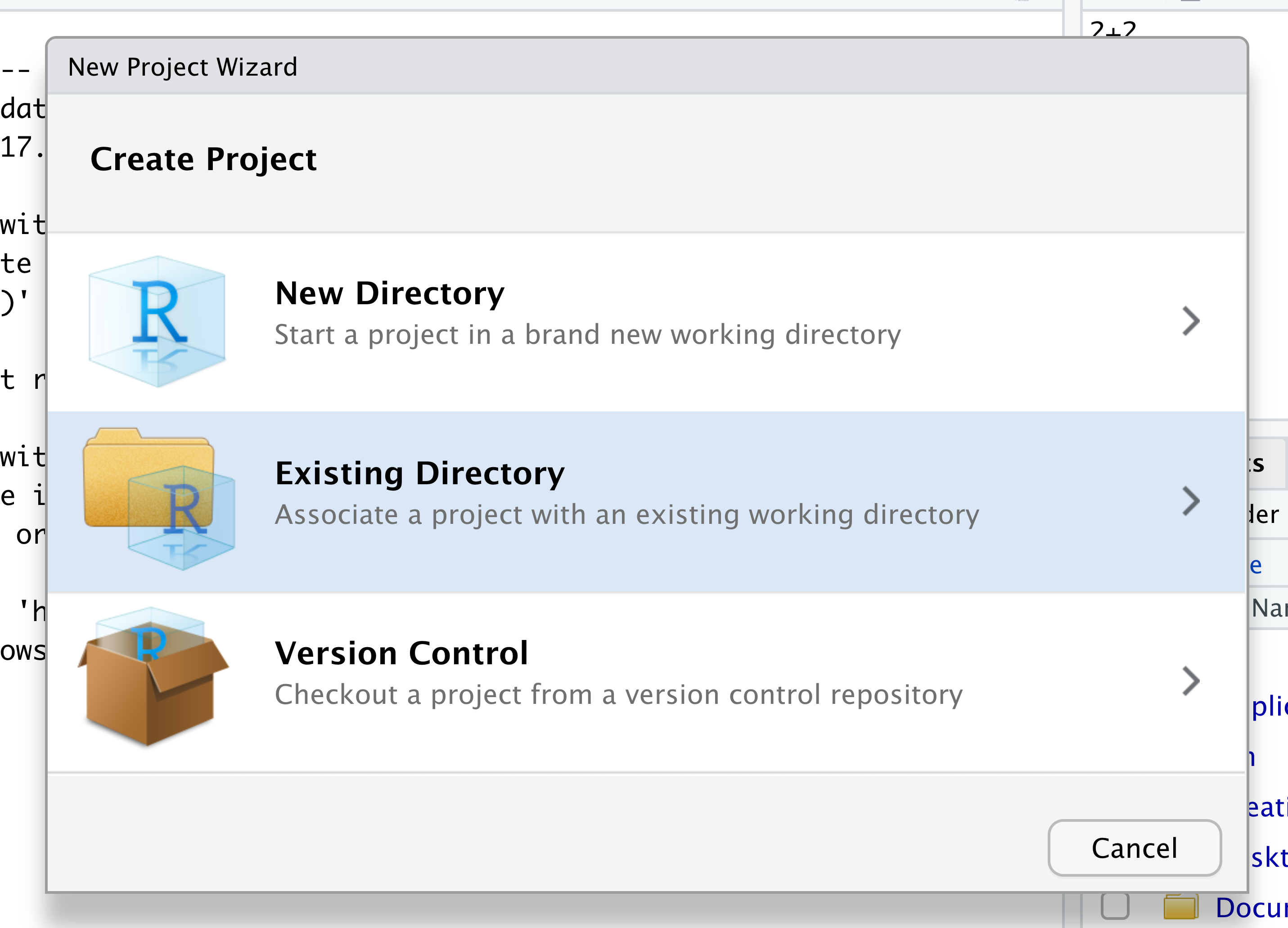
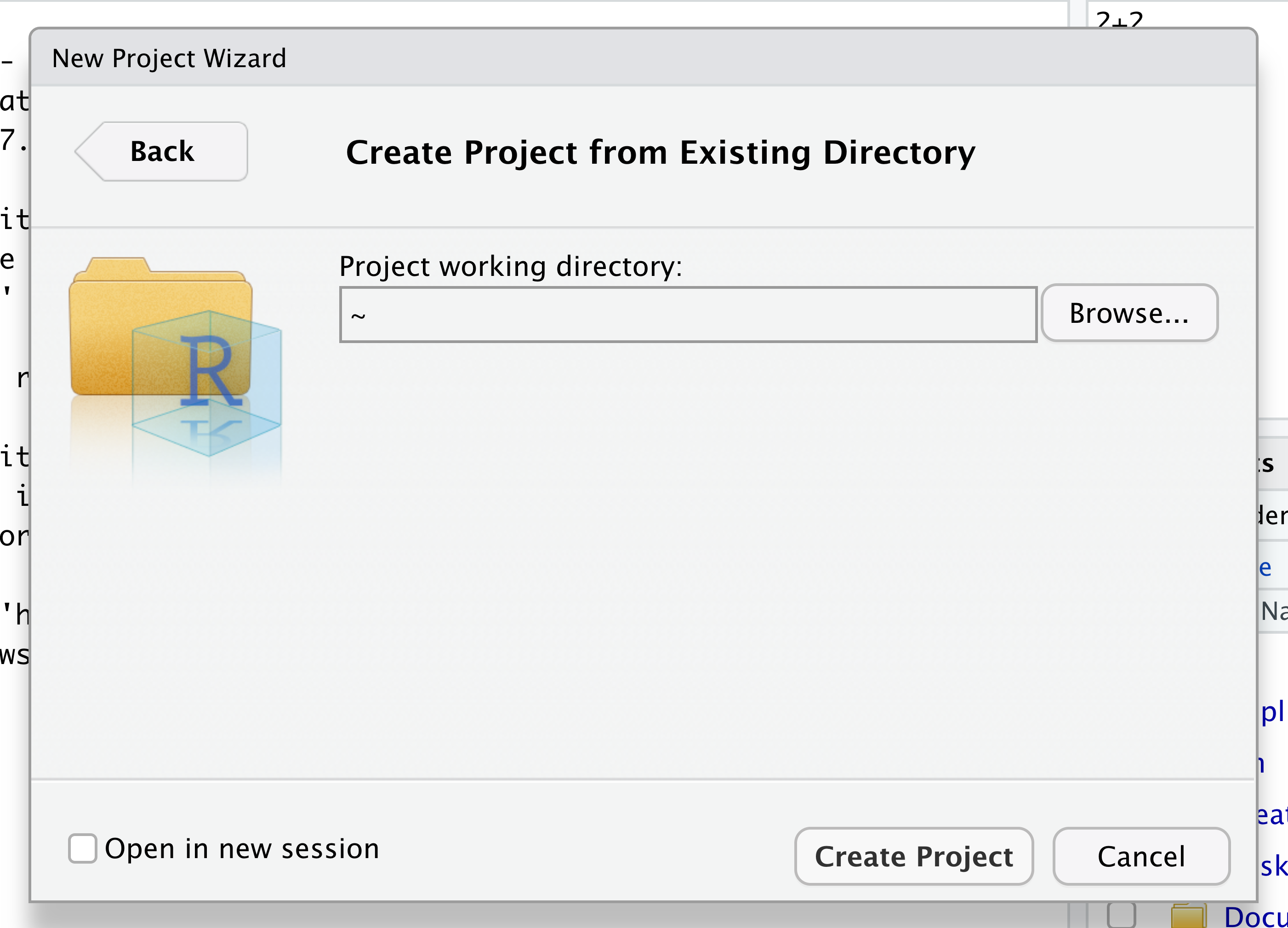
Navigate to the directory that contains your code and data from the setup instructions and click the “Open” button. Note that in the screenshots below, this folder says “un-report” - for us, it should say “ontario-report”.
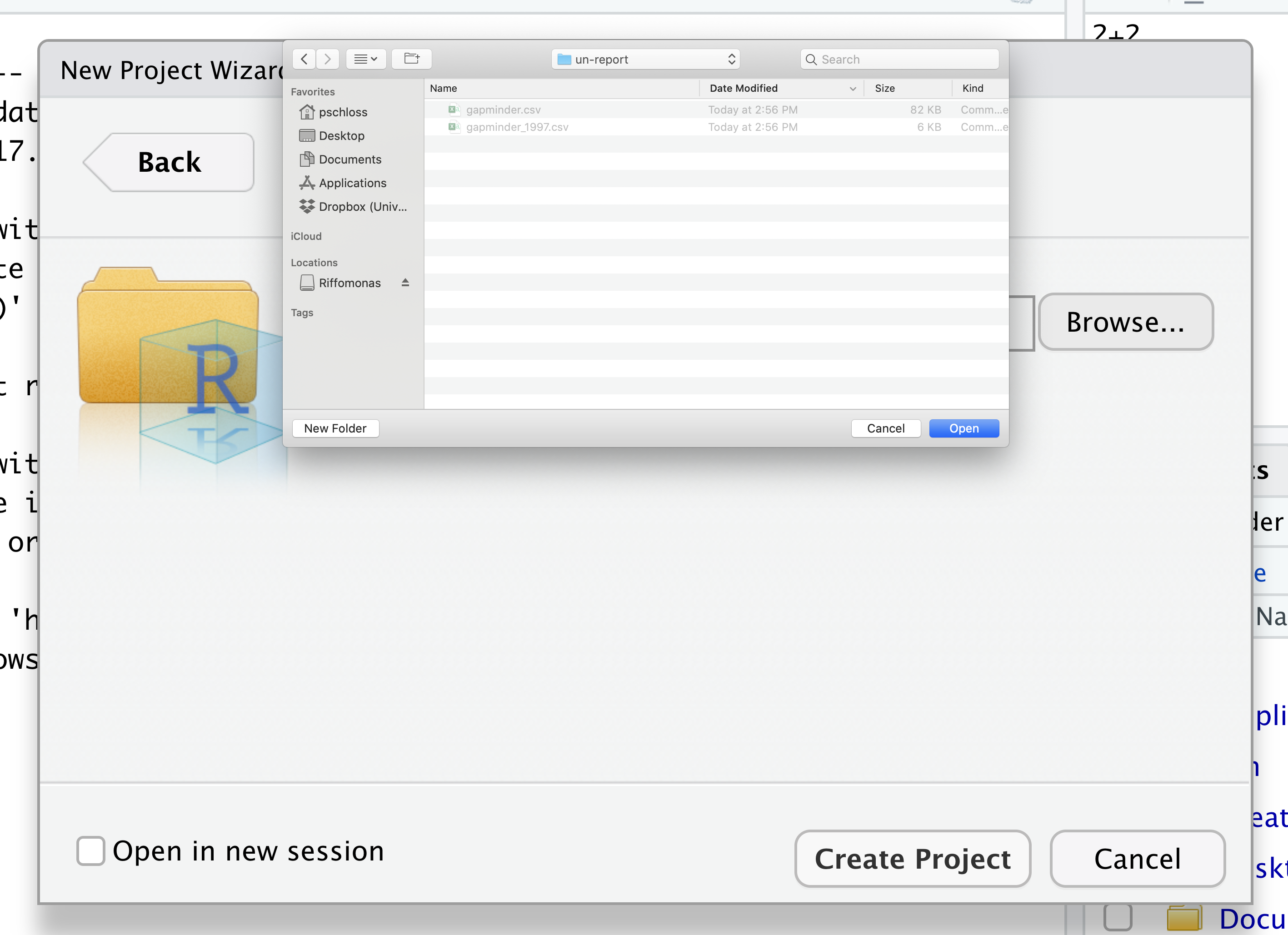
Then click the “Create Project” button.
Did you notice anything change?
In the lower right corner of your RStudio session, you should notice that your Files tab is now your project directory. You’ll also see a file called ontario-report.Rproj in that directory.
From now on, you should start RStudio by double clicking on that file. This will make sure you are in the correct directory when you run your analysis.
We’d like to create a file where we can keep track of our R code.
Back in the “File” menu, you’ll see the first option is “New File”. Selecting “New File” opens another menu to the right and the first option is “R Script”. Select “R Script”.
Now we have a fourth panel in the upper left corner of RStudio that includes an Editor tab with an untitled R Script. Let’s save this file as plotting.R in our project directory. Go to “File” -> “Save” and enter “plotting.R”
We will be entering R code into the Editor tab to run in our Console panel.
On line 1 of plotting.R, type 2+2.
With your cursor on the line with the 2+2, click the button that says Run. You should be able to see that 2+2 was run in the Console.
As you write more code, you can highlight multiple lines and then click Run to run all of the lines you have selected.
Introduction to the Tidyverse
In this session we will learn how to read data into R and plot it, allowing us to explore how environmental variables affect the microbes of Lake Ontario. We’ll use functions from the tidyverse to make working with our data easier.
The tidyverse vs Base R
If you’ve used R before, you may have learned commands that are different than the ones we will be using during this workshop. We will be focusing on functions from the tidyverse. The “tidyverse” is a collection of R packages that have been designed to work well together and offer many convenient features that do not come with a fresh install of R (aka “base R”). These packages are very popular and have a lot of developer support including many staff members from RStudio. These functions generally help you to write code that is easier to read and maintain. We believe learning these tools will help you become more productive more quickly.
Let’s start by loading a package called tidyverse. In plotting.R, type and run:
library(tidyverse)
Warning: package 'lubridate' was built under R version 4.3.3
── Attaching core tidyverse packages ─────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ───────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
What’s with all those messages???
When you loaded the
tidyversepackage, you probably got a message like the one we got above. Don’t panic! These messages are just giving you more information about what happened when you loadedtidyverse. Thetidyverseis actually a collection of several different packages, so the first section of the message tells us what packages were installed when we loadedtidyverse(these includeggplot2, which we’ll be using a lot in this lesson, anddyplr, which you’ll be introduced to tomorrow in the R for Data Analysis lesson).The second section of messages gives a list of “conflicts.” Sometimes, the same function name will be used in two different packages, and R has to decide which function to use. For example, our message says that:
dplyr::filter() masks stats::filter()This means that two different packages (
dyplrfromtidyverseandstatsfrom base R) have a function namedfilter(). By default, R uses the function that was most recently loaded, so if we try using thefilter()function after loadingtidyverse, we will be using thefilter()function > fromdplyr().
Pro-tip
Those of us that use R on a daily basis use cheat sheets to help us remember how to use various R functions.
You can find them in RStudio by going to the “Help” menu and selecting “Cheat Sheets”. The four that will be most helpful in this workshop are “Data Visualization with ggplot2”, “Data Transformation with dplyr”, “R Markdown Cheat Sheet”, and “R Markdown Reference Guide”.
For things that aren’t on the cheat sheets, Google is your best friend. Even expert coders use Google when they’re stuck or trying something new!
Loading and reviewing data
We will import a file containing data from Ontario samples called sample_data.csv. We will import it into R using a function from the tidyverse called read_csv:
sample_data <- read_csv("sample_data.csv")
Rows: 71 Columns: 9
── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (2): sample_id, env_group
dbl (7): depth, cells_per_ml, temperature, total_nitrogen, total_phosphorus, diss_org_carbon, chlorophyll
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
read_csvvs.read.csvWhen you began typing the
read_csvcommand, a very similarly named function,read.csv, may have popped up. These commands both do the same thing - they read in data from .csv files. Theread.csvfunction is from “base” R (the packages and code that is automatically loaded), whileread_csvis from thereadrpackage in the tidyverse. They are very similar and are often interchangeable. The way they print data tables in the console is different, though, as is how they handle messier data tables. In later lessons, these functions won’t be interchangeable for us. So to keep us consistent, please confirm that you are usingread_csv.
Look at the “Environment” tab. Here you will see a list of all the objects you’ve created or imported during your R session. Do you see an object called sample_data? Click on the small table to the right of sample_data to View our dataset. This is a quick way to browse your data to make sure everything looks like it has been imported correctly.
We see that our data has 9 columns (variables).
Each row contains a unique Sample Id (“sample_id”), the depth of the sample (“depth”, in meters), the number of microbial cells per mL (“cells_per_ml”), and environmental data like temperature (“temperature”, in °C), total nitrogen (“total_nitrogen”, in µg N/L), total phosphorus (“total_phosphorus”, in µg P/L), dissolved organic carbon (“diss_org_carbon”, in mg C/L), and Chlorophyll-a (“chlorophyll”, in µg/L).
The Sample ID corresponds to the month, station, and depth of the sample (E for “epilimnion”, M for “mid”, and B for “bottom”). Below, you can see a map of where these stations are in Lake Ontario. Stations 62 was only sampled in September, while Station 74 was only sampled in May.
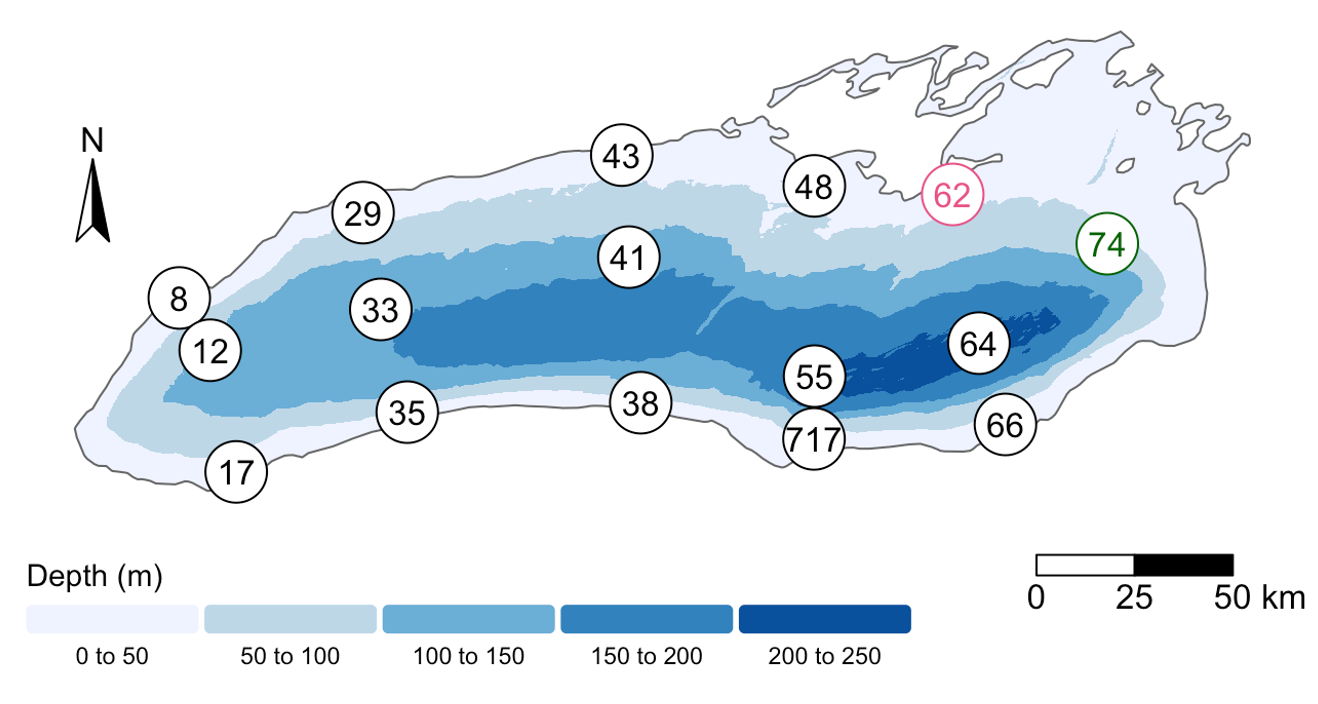
We also found that the samples fell into three main groups based on their depth (shallow vs. deep) and the month in which they were collected (May or September). Deep samples were similar between months, so they are in the same group. These classifications are held in the “env_group” column.
After we’ve reviewed the data, you’ll want to make sure to click the tab in the upper left to return to your plotting.R file so we can return to our R script.
Data frames vs. tibbles
Functions from the “tidyverse” such as
read_csvwork with objects called “tibbles”, which are a specialized kind of “data.frame.” Another common way to store data is a “data.table”. All of these types of data objects (tibbles, data.frames, and data.tables) can be used with the commands we will learn in this lesson to make plots. We may sometimes use these terms interchangeably.
Understanding commands
Let’s take a closer look at the read_csv command we typed.
Starting from the left, the first thing we see is sample_data. We viewed the contents of this file after it was imported so we know that sample_data acts as a placeholder for our data.
If we highlight just sample_data within our code file and press Ctrl+Enter on our keyboard, what do we see?
We should see a data table outputted, similar to what we saw in the Viewer tab.
In R terms, sample_data is a named object that references or stores something. In this case, sample_data stores a specific table of data.
When we’re coding in R, we often want to assign a value, or a collection of values, to an object, which means we gave those values a name. To create an object in R, we’ll use the <- symbol, which is the assignment operator. It assigns values generated or typed on the right to objects on the left. We can see our objects in the Environment pane.
An alternative symbol that you might see used as an assignment operator is the = but it is clearer to only use <- for assignment. We use this symbol so often that RStudio has a keyboard short cut for it: Alt+- on Windows, and Option+- on Mac. You can retrieve the values you stored by typing the name of the object.
Assigning values to objects
Try to assign values to some objects and observe each object after you have assigned a new value. What do you notice?
name <- "agar" name year <- 1881 year name <- "Fanny Hesse" nameSolution
When we assign a value to an object, the object stores that value so we can access it later. However, if we store a new value in an object we have already created (like when we stored “Fanny Hesse” in the
nameobject), it replaces the old value. Theyearobject does not change, because we never assign it a new value.
Guidelines on naming objects
- You want your object names to be explicit and not too long.
- They cannot start with a number (2x is not valid, but x2 is).
- R is case sensitive, so for example, weight_kg is different from Weight_kg.
- You cannot use spaces in the name.
- There are some names that cannot be used because they are the names of fundamental functions in R (e.g., if, else, for; see here for a complete list). If in doubt, check the help to see if the name is already in use (
?function_name).- It’s best to avoid dots (.) within names. Many function names in R itself have them and dots also have a special meaning (methods) in R and other programming languages.
- It is recommended to use nouns for object names and verbs for function names.
- Be consistent in the styling of your code, such as where you put spaces, how you name objects, etc. Using a consistent coding style makes your code clearer to read for your future self and your collaborators. One popular style guide can be found through the tidyverse.
Bonus Exercise: Bad names for objects
Try to assign values to some new objects. What do you notice? After running all four lines of code bellow, what value do you think the object
Flowerholds?1number <- 3 Flower <- "marigold" flower <- "rose" favorite number <- 12Solution
Notice that we get an error when we try to assign values to
1numberandfavorite number. This is because we cannot start an object name with a numeral and we cannot have spaces in object names. The objectFlowerstill holds “marigold.” This is because R is case-sensitive, so runningflower <- "rose"does NOT change theFlowerobject. This can get confusing, and is why we generally avoid having objects with the same name and different capitalization.
The next part of the command is read_csv("sample_data.csv"). This has a few different key parts. The first part is the read_csv function. You call a function in R by typing it’s name followed by opening then closing parenthesis. Each function has a purpose, which is often hinted at by the name of the function. Let’s try to run the function without anything inside the parenthesis.
read_csv()
Error in read_csv(): argument "file" is missing, with no default
We get an error message. Don’t panic! Error messages pop up all the time, and can be super helpful in debugging code.
In this case, the message tells us “argument “file” is missing, with no default.” Many functions, including read_csv, require additional pieces of information to do their job. We call these additional values “arguments” or “parameters.” You pass arguments to a function by placing values in between the parenthesis. A function takes in these arguments and does a bunch of “magic” behind the scenes to output something we’re interested in.
For example, when we loaded in our data, the command contained "sample_data.csv" inside the read_csv() function. This is the value we assigned to the file argument. But we didn’t say that that was the file. How does that work?
Pro-tip
Each function has a help page that documents what arguments the function expects and what value it will return. You can bring up the help page a few different ways. You can go to the “Help” tab in the lower right and search for a function. You can also type
?followed by the function name in the console.For example, try running
?read_csv. A help page should pop up with information about what the function is used for and how to use it, as well as useful examples of the function in action. As you can see, the first argument ofread_csvis the file path.
The read_csv() function took the file path we provided, did who-knows-what behind the scenes, and then outputted an R object with the data stored in that csv file. All that, with one short line of code!
Do all functions need arguments? Let’s test some other functions:
Sys.Date()
[1] "2025-01-16"
getwd()
"/Users/augustuspendleton/Desktop/ontario-report"
While some functions, like those above, don’t need any arguments, in other
functions we may want to use multiple arguments. When we’re using multiple
arguments, we separate the arguments with commas. For example, we can use the
sum() function to add numbers together:
sum(5, 6)
[1] 11
Learning more about functions
Look up the function
round. What does it do? What will you get as output for the following lines of code?round(3.1415) round(3.1415,3)Solution
roundrounds a number. By default, it rounds it to zero digits (in our example above, to 3). If you give it a second number, it rounds it to that number of digits (in our example above, to 3.142)
Notice how in this example, we didn’t include any argument names. But you can use argument names if you want:
read_csv(file = 'sample_data.csv')
Rows: 71 Columns: 9
── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (2): sample_id, env_group
dbl (7): depth, cells_per_ml, temperature, total_nitrogen, total_phosphorus, diss_org_carbon, chlorophyll
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# A tibble: 71 × 9
sample_id env_group depth cells_per_ml temperature total_nitrogen total_phosphorus diss_org_carbon chlorophyll
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 May_12_B Deep 103. 2058864. 4.07 465 3.78 2.48 0.05
2 May_12_E Shallow_May 5 4696827. 7.01 465 4.39 2.38 2.53
3 May_12_M Shallow_May 15 4808339. 6.14 474 5.37 2.60 3.2
4 May_17_E Shallow_May 5 3738681. 5.99 492 4.67 2.44 0.55
5 May_29_B Deep 27 2153086. 4.67 525 4.44 2.40 0.48
6 May_29_E Shallow_May 5 3124920. 5.97 521 3.71 2.28 0.79
7 May_29_M Shallow_May 19 2566156. 5.69 539 4.23 2.33 0.44
8 May_33_B Deep 135 2293177. 3.87 505 4.18 2.34 0.22
9 May_33_E Shallow_May 5 5480859. 7.93 473 6.64 2.51 3.44
10 May_33_M Shallow_May 20 3114433. 4.53 515 4.14 2.23 1.27
# ℹ 61 more rows
Position of the arguments in functions
Which of the following lines of code will give you an output of 3.14? For the one(s) that don’t give you 3.14, what do they give you?
round(x = 3.1415) round(x = 3.1415, digits = 2) round(digits = 2, x = 3.1415) round(2, 3.1415)Solution
The 2nd and 3rd lines will give you the right answer because the arguments are named, and when you use names the order doesn’t matter. The 1st line will give you 3 because the default number of digits is 0. Then 4th line will give you 2 because, since you didn’t name the arguments, x=2 and digits=3.1415.
Sometimes it is helpful - or even necessary - to include the argument name, but often we can skip the argument name, if the argument values are passed in a certain order. If all this function stuff sounds confusing, don’t worry! We’ll see a bunch of examples as we go that will make things clearer.
Comments
Sometimes you may want to write comments in your code to help you remember what your code is doing, but you don’t want R to think these comments are a part of the code you want to evaluate. That’s where comments come in! Anything after a
#symbol in your code will be ignored by R. For example, let’s say we wanted to make a note of what each of the functions we just used do:Sys.Date() # outputs the current date[1] "2025-01-16"getwd() # outputs our current working directory (folder)[1] "/Users/augustuspendleton/Desktop/Coding/Carpentries_Workshops/Cornell_Carpentries_Jan2025/_episodes_rmd"sum(5, 6) # adds numbers[1] 11read_csv(file = 'sample_data.csv') # reads in csv fileRows: 71 Columns: 9 ── Column specification ─────────────────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr (2): sample_id, env_group dbl (7): depth, cells_per_ml, temperature, total_nitrogen, total_phosphorus, diss_org_carbon, chlorophyll ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 71 × 9 sample_id env_group depth cells_per_ml temperature total_nitrogen total_phosphorus diss_org_carbon chlorophyll <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 May_12_B Deep 103. 2058864. 4.07 465 3.78 2.48 0.05 2 May_12_E Shallow_May 5 4696827. 7.01 465 4.39 2.38 2.53 3 May_12_M Shallow_May 15 4808339. 6.14 474 5.37 2.60 3.2 4 May_17_E Shallow_May 5 3738681. 5.99 492 4.67 2.44 0.55 5 May_29_B Deep 27 2153086. 4.67 525 4.44 2.40 0.48 6 May_29_E Shallow_May 5 3124920. 5.97 521 3.71 2.28 0.79 7 May_29_M Shallow_May 19 2566156. 5.69 539 4.23 2.33 0.44 8 May_33_B Deep 135 2293177. 3.87 505 4.18 2.34 0.22 9 May_33_E Shallow_May 5 5480859. 7.93 473 6.64 2.51 3.44 10 May_33_M Shallow_May 20 3114433. 4.53 515 4.14 2.23 1.27 # ℹ 61 more rows
Creating our first plot
We will be using the ggplot2 package today to make our plots. This is a very
powerful package that creates professional looking plots and is one of the
reasons people like using R so much. All plots made using the ggplot2 package
start by calling the ggplot() function. So in the tab you created for the
plotting.R file, type the following:
ggplot(data=sample_data)

To run code that you’ve typed in the editor, you have a few options. Remember that the quickest way to run the code is by pressing Ctrl+Enter on your keyboard. This will run the line of code that currently contains your cursor or any highlighted code.
When we run this code, the Plots tab will pop to the front in the lower right corner of the RStudio screen. Right now, we just see a big grey rectangle.
What we’ve done is created a ggplot object and told it we will be using the data
from the sample_data object that we’ve loaded into R. We’ve done this by
calling the ggplot() function with sample_data as the data argument.
So we’ve made a plot object, now we need to start telling it what we actually
want to draw in this plot. The elements of a plot have a bunch of properties
like an x and y position, a size, a color, etc. These properties are called
aesthetics. When creating a data visualization, we map a variable in our
dataset to an aesthetic in our plot. In ggplot, we can do this by creating an
“aesthetic mapping”, which we do with the aes() function.
To create our plot, we need to map variables from our sample_data object to
ggplot aesthetics using the aes() function. Since we have already told
ggplot that we are using the data in the sample_data object, we can
access the columns of sample_data using the object’s column names.
(Remember, R is case-sensitive, so we have to be careful to match the column
names exactly!)
We are interested in whether there is a relationship between temperature and microbial abundance, so let’s start by telling our plot object that we want to map our
temperature values to the x axis of our plot. We do this by adding (+) information to
our plot object. Add this new line to your code and run both lines by
highlighting them and pressing Ctrl+Enter on your
keyboard:
ggplot(data = sample_data) +
aes(x = temperature)
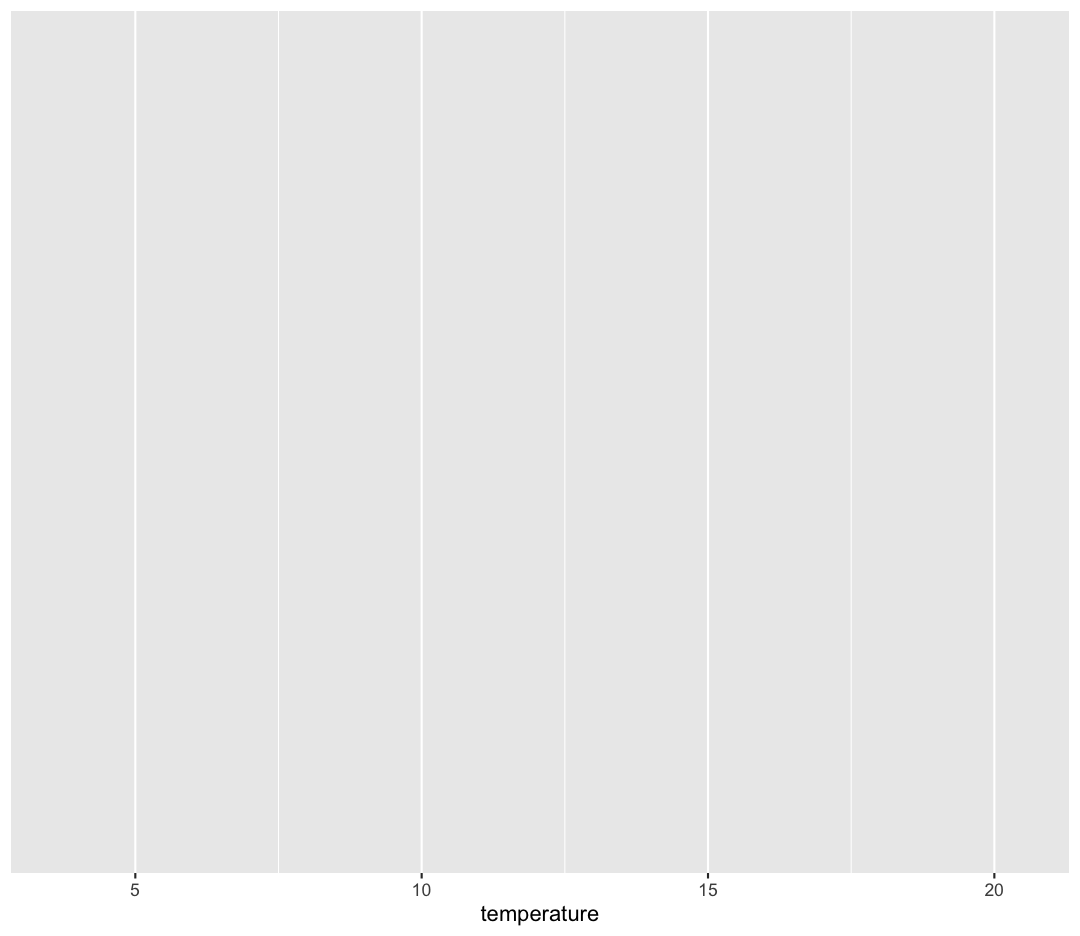
Note that we’ve added this new function call to a second line just to make it
easier to read. To do this we make sure that the + is at the end of the first
line otherwise R will assume your command ends when it starts the next row. The
+ sign indicates not only that we are adding information, but to continue on
to the next line of code.
Observe that our Plot window is no longer a grey square. We now see that
we’ve mapped the temperature column to the x axis of our plot. Note that that
column name isn’t very pretty as an x-axis label, so let’s add the labs()
function to make a nicer label for the x axis
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)")
OK. That looks better.
Quotes vs No Quotes
Notice that when we added the label value we did so by placing the values inside quotes. This is because we are not using a value from inside our data object - we are providing the name directly. When you need to include actual text values in R, they will be placed inside quotes to tell them apart from other object or variable names.
The general rule is that if you want to use values from the columns of your data object, then you supply the name of the column without quotes, but if you want to specify a value that does not come from your data, then use quotes.
Mapping cell abundance to the y axis
Map our
cells_per_mlvalues to the y axis and give them a nice label.Solution
ggplot(data = sample_data) + aes(x = temperature) + labs(x = "Temperature (C)") + aes(y = cells_per_ml) + labs(y = "Cells per mL")
Excellent. We’ve now told our plot object where the x and y values are coming
from and what they stand for. But we haven’t told our object how we want it to
draw the data. There are many different plot types (bar charts, scatter plots,
histograms, etc). We tell our plot object what to draw by adding a “geometry”
(“geom” for short) to our object. We will talk about many different geometries
today, but for our first plot, let’s draw our data using the “points” geometry
for each value in the data set. To do this, we add geom_point() to our plot
object:
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml) +
labs(y = "Cells per mL") +
geom_point()
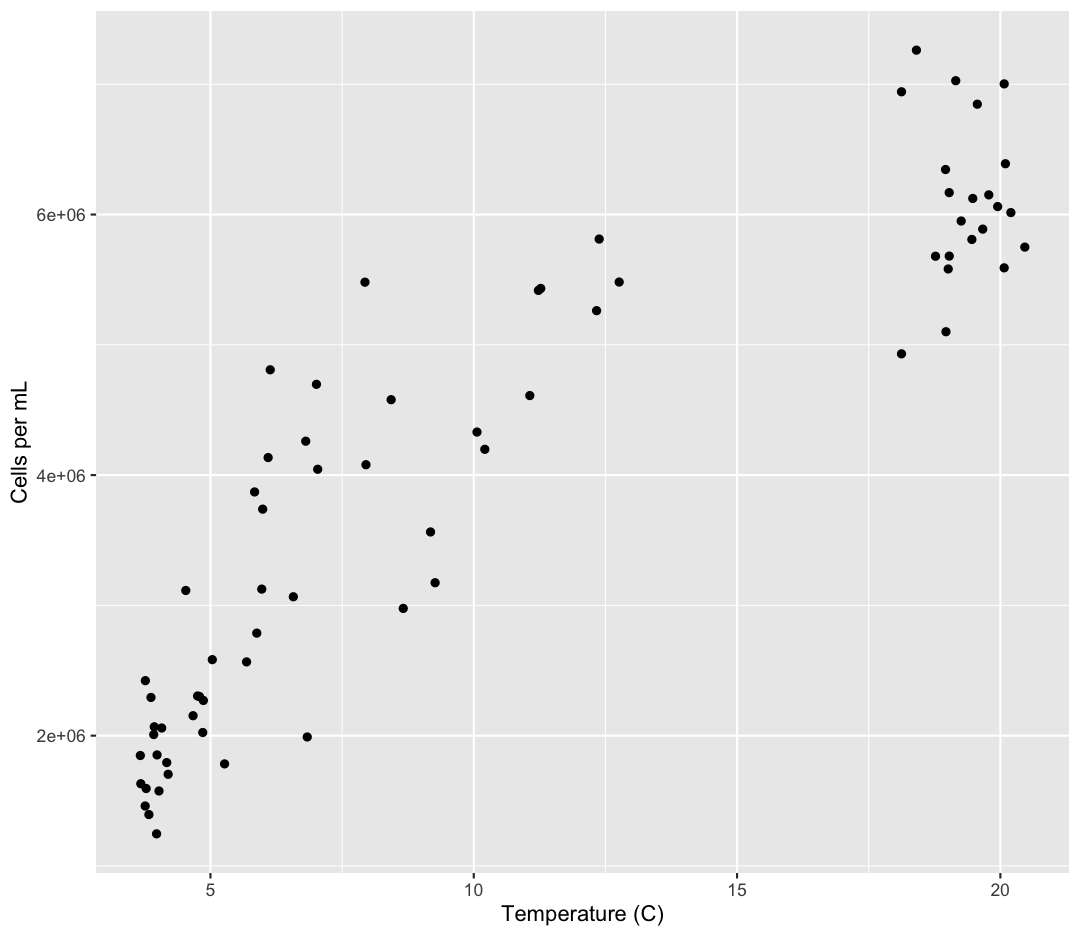
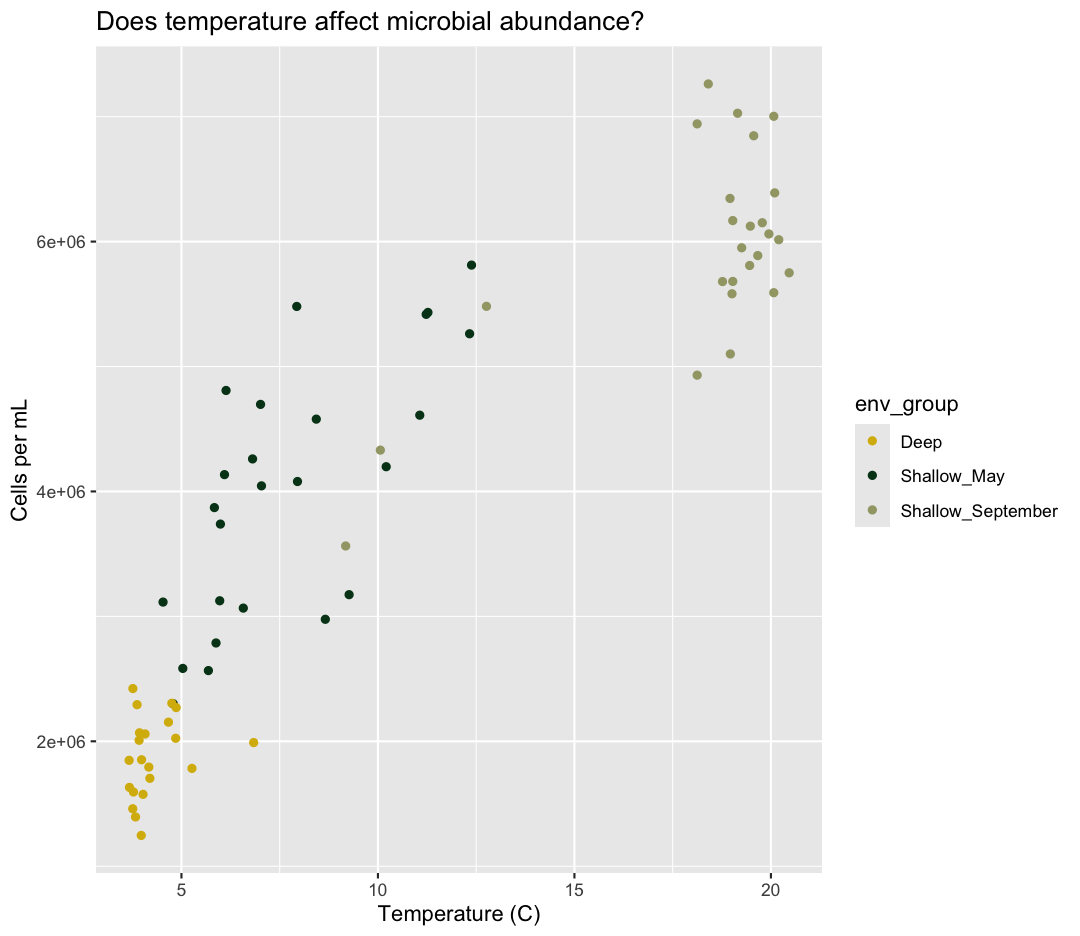
Now we’re really getting somewhere. It finally looks like a proper plot! We can
now see a trend in the data. It looks like samples with a higher temperature tend to
have a higher cell abundance. Let’s add a title to our plot to make that
clearer. Again, we will use the labs() function, but this time we will use the
title = argument.
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml) +
labs(y = "Cells per mL") +
geom_point() +
labs(title = "Does temperature affect microbial abundance?")
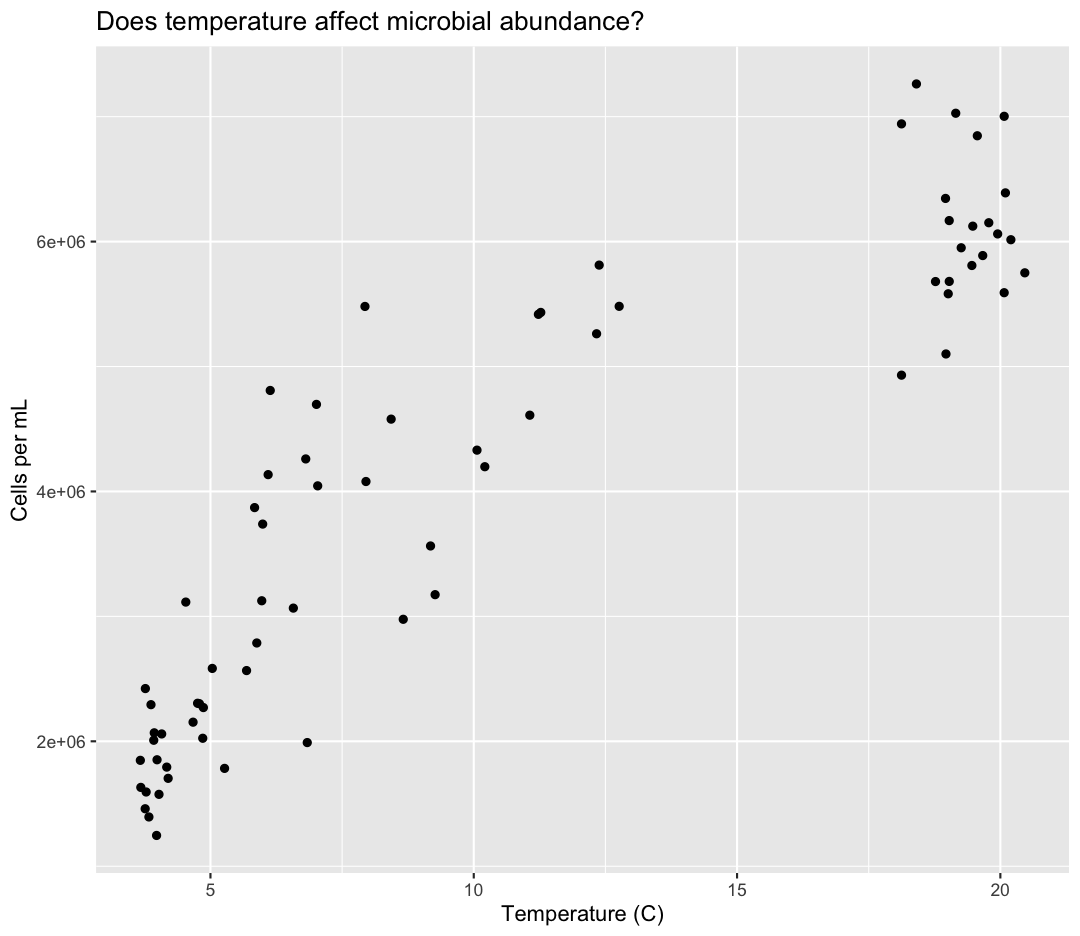
No one can deny we’ve made a very handsome plot! But now looking at the data, we
might be curious about learning more - for example, it seems like the data separates into at least two distinct groups. We know that there are pieces of data in the sample_data
object that we haven’t used yet. Maybe we are curious if the trend between temperature and cell abundance is consistent between our three environmental groups. One thing we
could do is use a different color for each of these groups. To map the
env_group of each point to a color, we will again use the aes() function:
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml) +
labs(y = "Cells per mL") +
geom_point() +
labs(title = "Does temperature affect microbial abundance?") +
aes(color = env_group)
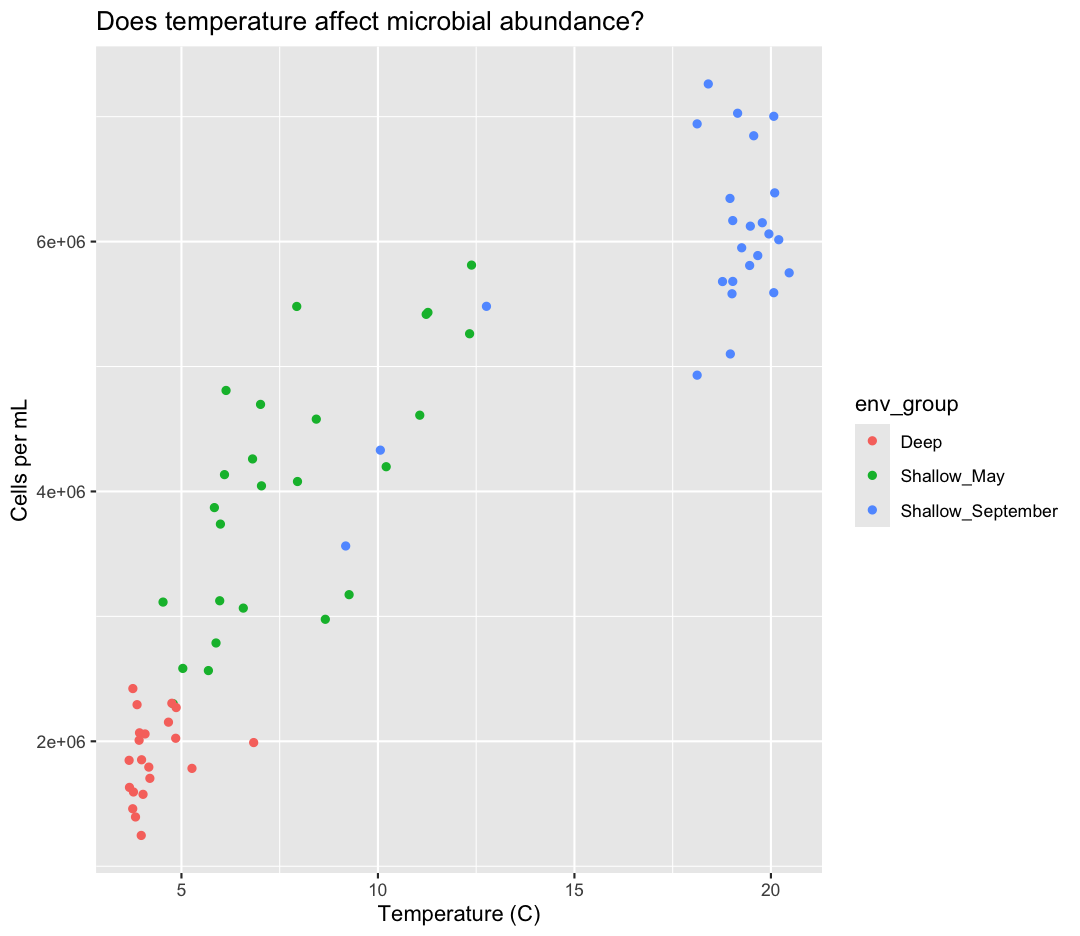
Here we can see that Deep samples have fewer cells than Shallow samples. Notice that when we add a mapping for
color, ggplot automatically provided a legend for us. It took care of assigning
different colors to each of our unique values of the env_group variable. (Note
that when we mapped the x and y values, those drew the actual axis labels, so in
a way the axes are like the legends for the x and y values).
What other variables might we expect to affect cell abundance? Perhaps microbial cell abundance is correlated to other measures of productivity, like the abundance of phytoplankton. Let’s find out by mapping the chlorophyll levels of each sample to the size of our points.
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml) +
labs(y = "Cells per mL") +
geom_point() +
labs(title = "Does temperature affect microbial abundance?") +
aes(color = env_group) +
aes(size = chlorophyll)
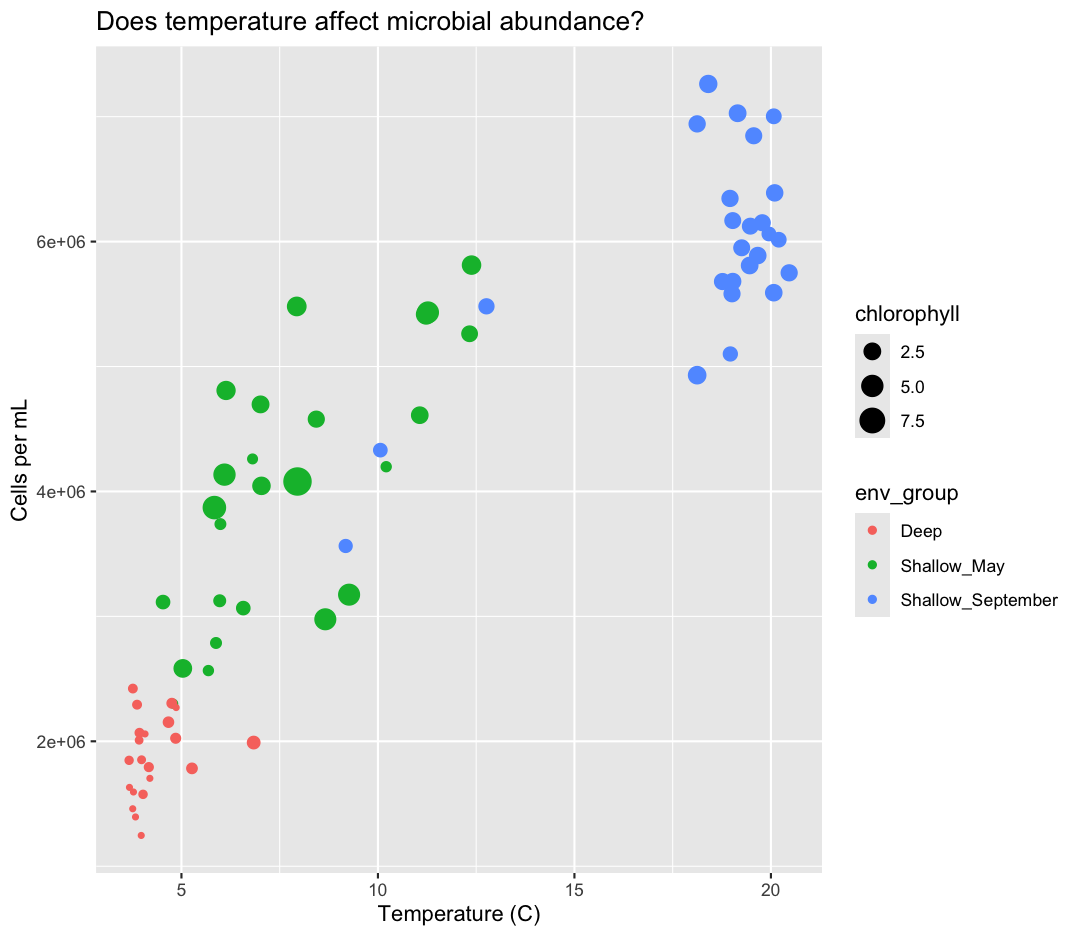
There doesn’t seem to be a very strong association with chlorophyll, besides low chlorophyll in deep samples. We got another legend here for size
which is nice, but the titles aren’t very informative. Let’s change those, using another calls to labs()
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml) +
labs(y = "Cells per mL") +
geom_point() +
labs(title = "Does temperature affect microbial abundance?") +
aes(color = env_group) +
aes(size = chlorophyll) +
labs(size = "Chlorophyll (ug/L)",
color = "Environmental Group")
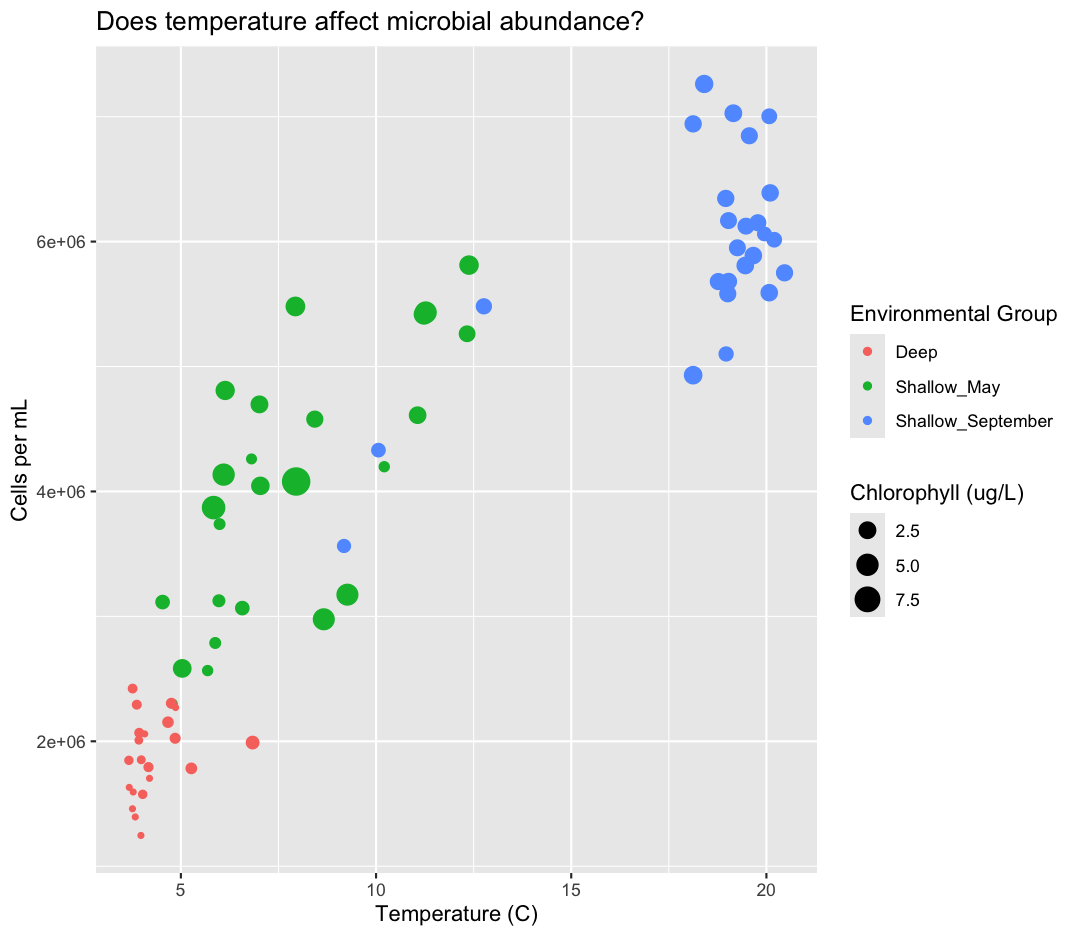
While we’re at it, I don’t love the scientific notation along the y-axis. Let’s change it by dividing our cells_per_ml by 1,000,000 and updating our axis title to match.
ggplot(data = sample_data) +
aes(x = temperature) +
labs(x = "Temperature (C)") +
aes(y = cells_per_ml/1000000) +
labs(y = "Cells (millions/mL)") +
geom_point() +
labs(title = "Does temperature affect microbial abundance?") +
aes(color = env_group) +
aes(size = chlorophyll) +
labs(size = "Chlorophyll (ug/L)",
color = "Environmental Group")
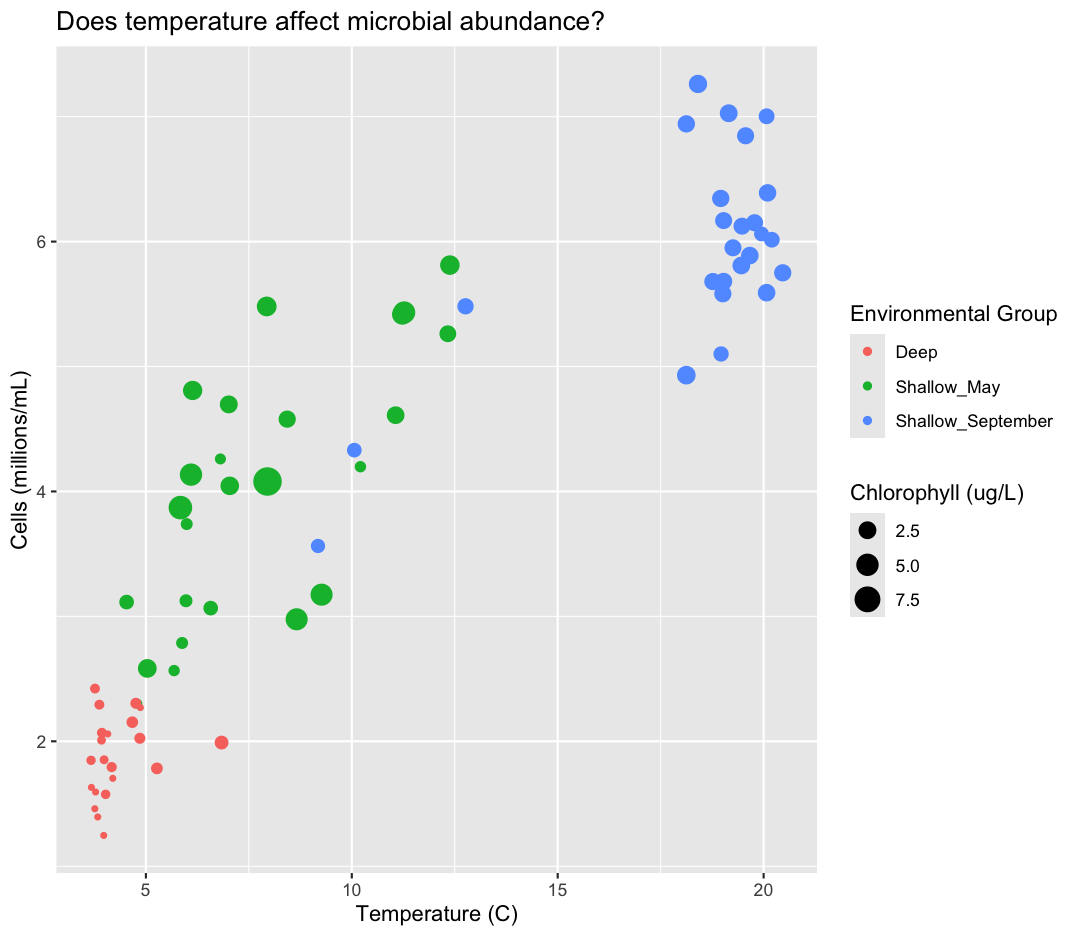
This works because you can treat the columns in the aesthetic mappings just like any other variables and can use functions to transform or change them at plot time rather than having to transform your data first.
Good work! Take a moment to appreciate what a cool plot you made with a few lines of code. In order to fully view its beauty you can click the “Zoom” button in the Plots tab - it will break free from the lower right corner and open the plot in its own window.
Changing shapes
Instead of (or in addition to) color, change the shape of the points so each env_group has a different shape. (I’m not saying this is a great thing to do - it’s just for practice!) HINT: Is size an aesthetic or a geometry? If you’re stuck, feel free to Google it, or look at the help menu.
Solution
You’ll want to use the
aesaesthetic function to change the shape:ggplot(data = sample_data) + aes(x = temperature) + labs(x = "Temperature (C)") + aes(y = cells_per_ml/1000000) + labs(y = "Cells (millions/mL)") + geom_point() + labs(title = "Does temperature affect microbial abundance?") + aes(color = env_group) + aes(size = chlorophyll) + aes(shape = env_group) + labs(size = "Chlorophyll (ug/L)", color = "Environmental Group", shape = "Environmental Group")
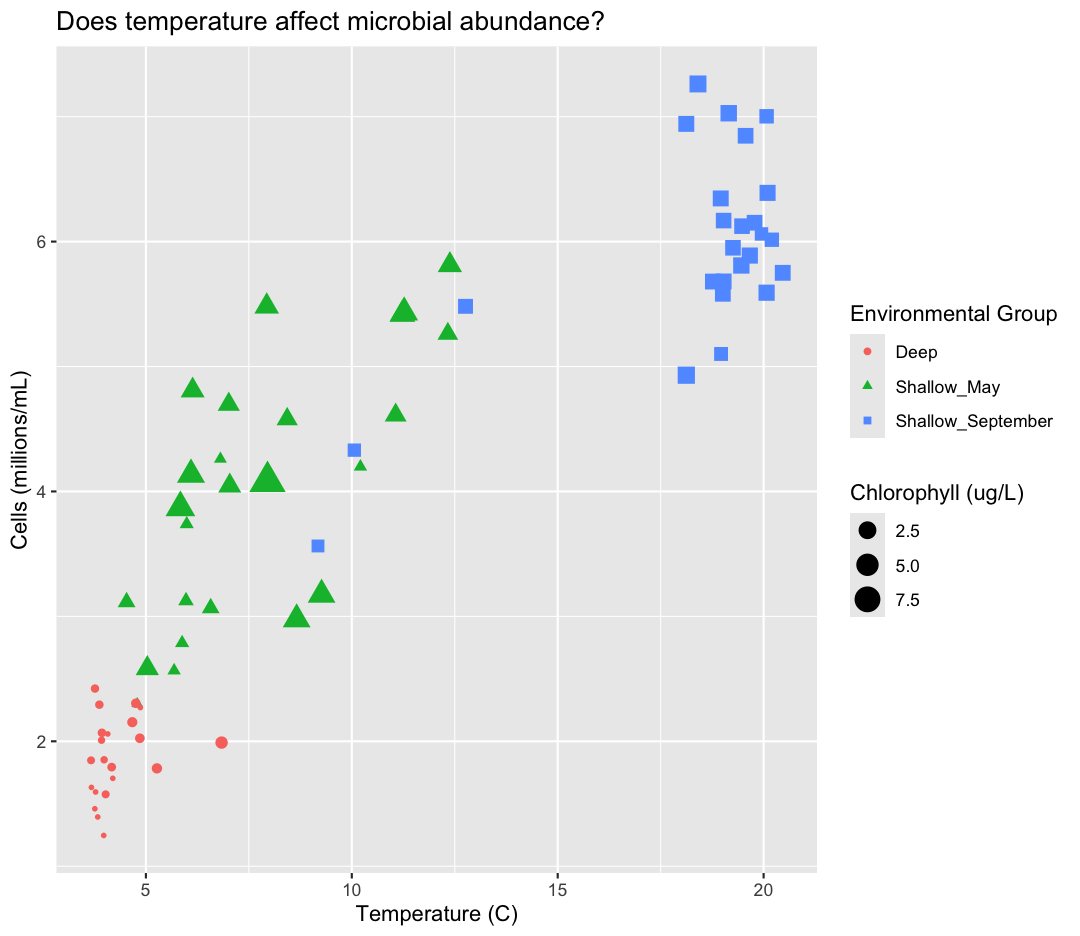
For our first plot we added each line of code one at a time so you could see the
exact affect it had on the output. But when you start to make a bunch of plots,
we can actually combine many of these steps so you don’t have to type as much.
For example, you can collect all the aes() statements and all the labs()
together. A more condensed version of the exact same plot would look like this:
ggplot(data = sample_data) +
aes(x = temperature,
y = cells_per_ml/1000000,
color = env_group,
size = chlorophyll) +
geom_point() +
labs(x = "Temperature (C)",
y = "Cells (millions/mL)",
title = "Does temperature affect microbial abundance?",
size = "Chlorophyll (ug/L)",
color = "Environmental Group")
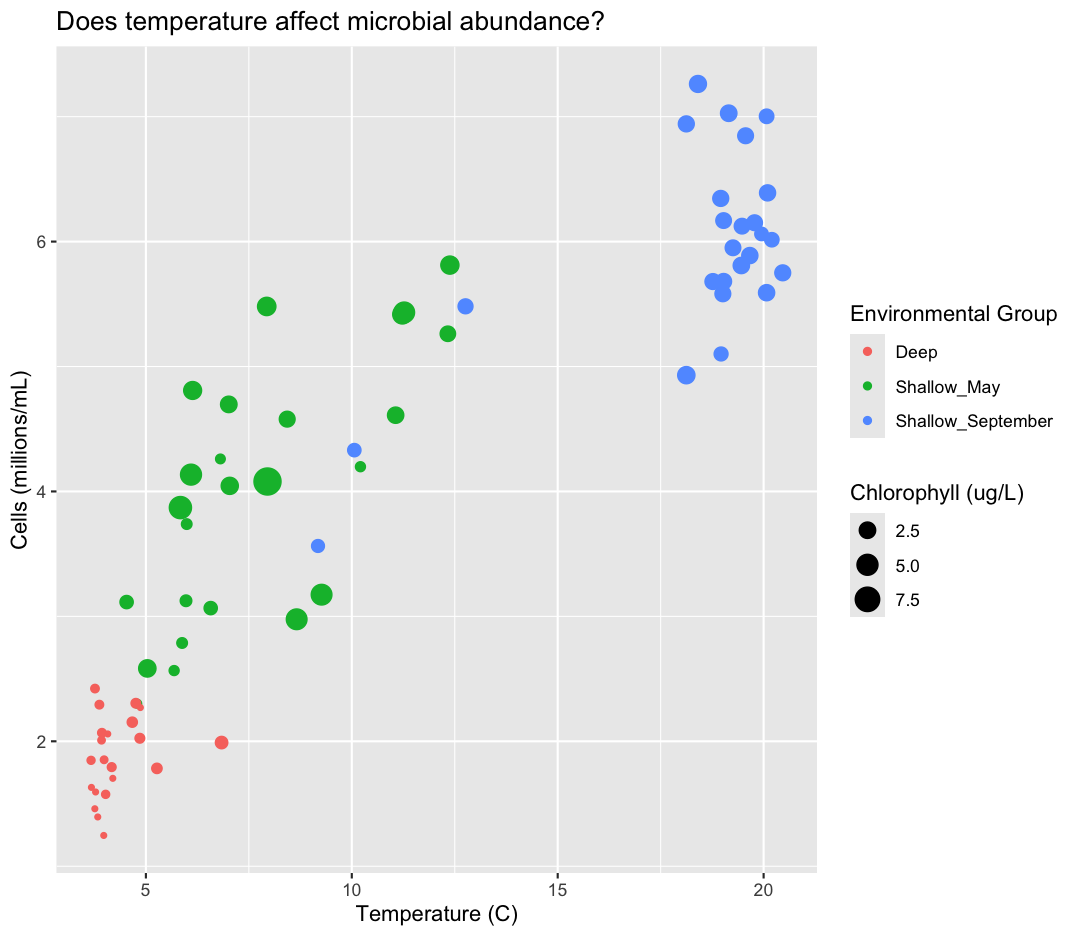
Plotting for data exploration
Within a project, we often have to work with many different data types, which require different methods of analysis and visualization. One of the most enjoyable parts of data analysis is trying out different plotting techniques to find patterns in your data.
Importing datasets
In the first plot, we found that temperature had a major influence on microbial abundance in Lake Ontario. We also learned, using color, that deep samples have cool temperatures, and water temperatures were colder in May compared to September. However, our sample_data object only contained data from two sampling time points. It would be useful for us to understand how temperatures vary in Lake Ontario over a fuller time series.
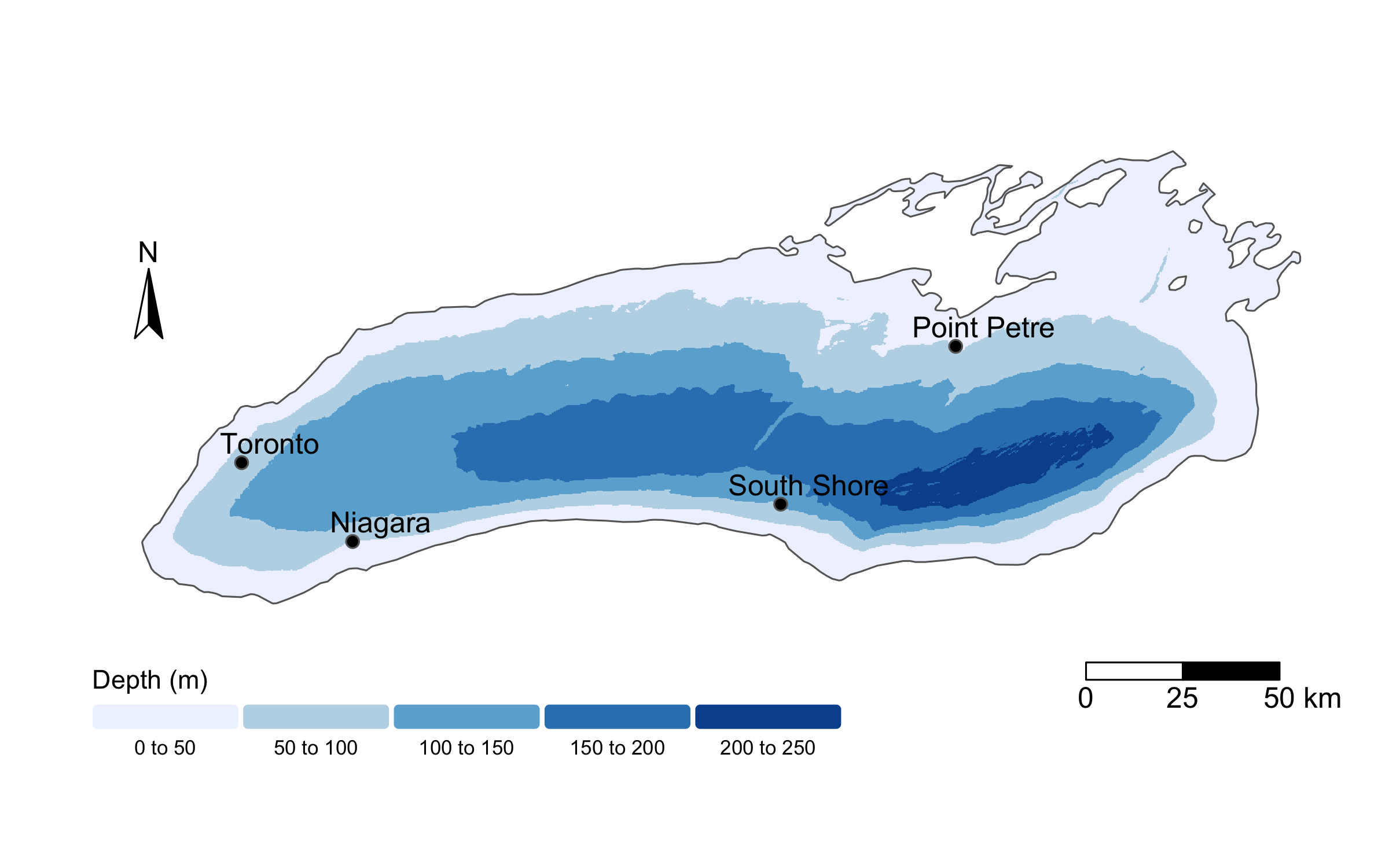
To do so, we will read in a new dataset, called buoy_data.csv. This file contains daily temperature measurements from buoys across Lake Ontario in 2023, collected and provided by the Ontario Ministry of Natural Resources, Fisheries and Oceans Canada, the U.S. Fish and Wildlife Service, U.S. Geological Survey, and Queen’s University. Raw data are publicly available through the GLOS Seagull platform, though today we’ll be working with a cleaned and simplified version of the dataset. Below, I show a map of the buoys whose data we’ll analyze.
To start, we will read in the data using read_csv.
Read in your own data
What argument should be provided in the below code to read in the full dataset?
buoy_data <- read_csv()Solution
buoy_data <- read_csv("buoy_data.csv")
Let’s take a look at the full dataset. We could use View(), the way we did for the smaller dataset, but if your data is too big, it might take too long to load. Luckily, R offers a way to look at parts of the data to get an idea of what your dataset looks like, without having to examine the whole thing. Here are some commands that allow us to get the dimensions of our data and look at a snapshot of the data. Try them out!
dim(buoy_data)
[1] 2945 6
head(buoy_data)
# A tibble: 6 × 6
sensor buoy depth day_of_year month temperature
<chr> <chr> <chr> <dbl> <chr> <dbl>
1 Niagara_Bottom Niagara Bottom 1 January 3.81
2 Niagara_Bottom Niagara Bottom 2 January 3.80
3 Niagara_Bottom Niagara Bottom 3 January 3.76
4 Niagara_Bottom Niagara Bottom 4 January 3.56
5 Niagara_Bottom Niagara Bottom 5 January 3.18
6 Niagara_Bottom Niagara Bottom 6 January 3.19
This dataset has six variables. We have four buoy locations (“Niagara”, “Toronto”,”South Shore”, and “Point Petre”), and temperature sensors at two depths: the surface and the bottom for each location. sensor is a combination of these values, to create a unique idea for each temperature sensor. We also have day_of_year, where 1 corresponds to January 1st and 365 corresponds to 365. We also have the month that sample was collected. Finally, we have temperature, in degrees Celsius.
Predicting
ggplotoutputsNow that we have the full dataset read into our R session, let’s plot the data placing
day_of_yearvariable on the x axis and temperature on the y axis. We’ve provided the code below. Notice that we’ve collapsed the plotting function options and left off some of the labels so there’s not as much code to work with. Before running the code, read through it and see if you can predict what the plot output will look like. Then run the code and check to see if you were right!ggplot(data = buoy_data) + aes(x=day_of_year, y=temperature, color=depth) + geom_point()
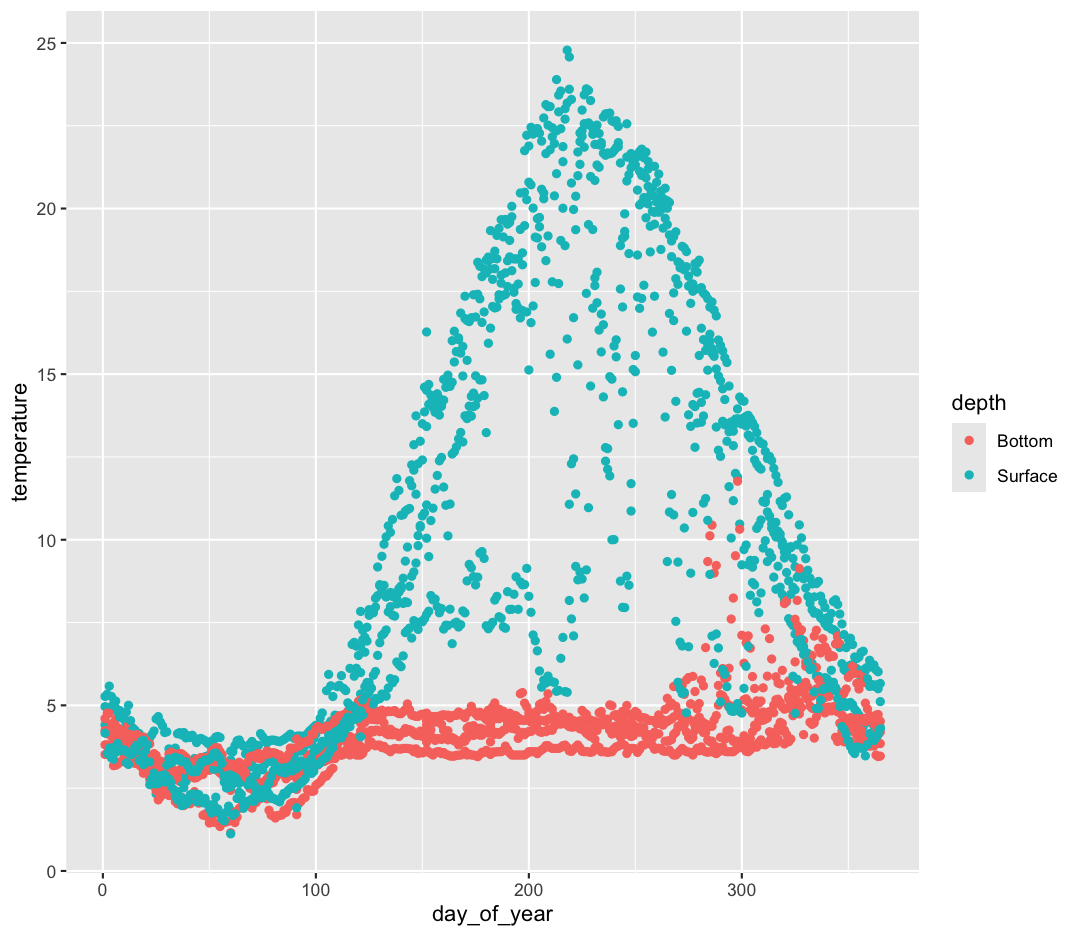
Hmm, the plot we created in the last exercise is a good start but it’s hard to tell which points should be connected in this time series. What’s going on? Since the dataset is more complex, the plotting options we used for the smaller dataset aren’t as useful for interpreting these data. Luckily, we can add additional attributes to our plots that will make patterns more apparent. For example, we can generate a different type of plot – perhaps a line plot – and assign attributes for columns where we might expect to see patterns.
Let’s review the columns and the types of data stored in our dataset to decide how we should group things together. To get an overview of our data object, we can look at the structure of buoy_data using the str() function.
str(buoy_data)
Pro-tip
The tidyverse also comes with a function for quickly seeing the structure of your
data.framecalledglimpse(). Try it and compare to the output fromstr()!
(You can also review the structure of your data in the Environment tab by clicking on the blue circle with the arrow in it next to your data object name.)
So, what do we see? The column names are listed after a $ symbol, and then we have a : followed by a text label. These labels correspond to the type of data stored in each column.
What kind of data do we see?
- “num” = Numeric (or non-whole number)
- “chr” = Character (categorical data)
Depending on the function and your R version, you may also see “int” or “dbl”, which corresponds to “integer” (whole numbers) and “double” (numbers with decimals).
Note In anything before R 4.0, categorical variables used to be read in as factors, which are a special data object that are used to store categorical data and have limited numbers of unique values. The unique values of a factor are tracked via the “levels” of a factor. A factor will always remember all of its levels even if the values don’t actually appear in your data. The factor will also remember the order of the levels and will always print values out in the same order (by default this order is alphabetical).
If your columns are stored as character values but you need factors for plotting, ggplot will convert them to factors for you as needed.
Our plot has a lot of points in columns which makes it hard to see trends over time. A better way to view the data showing changes over time is to use a line plot. Let’s try changing the geom to a line and see what happens.
ggplot(data = buoy_data) +
aes(x = day_of_year, y = temperature, color = depth) +
geom_line()
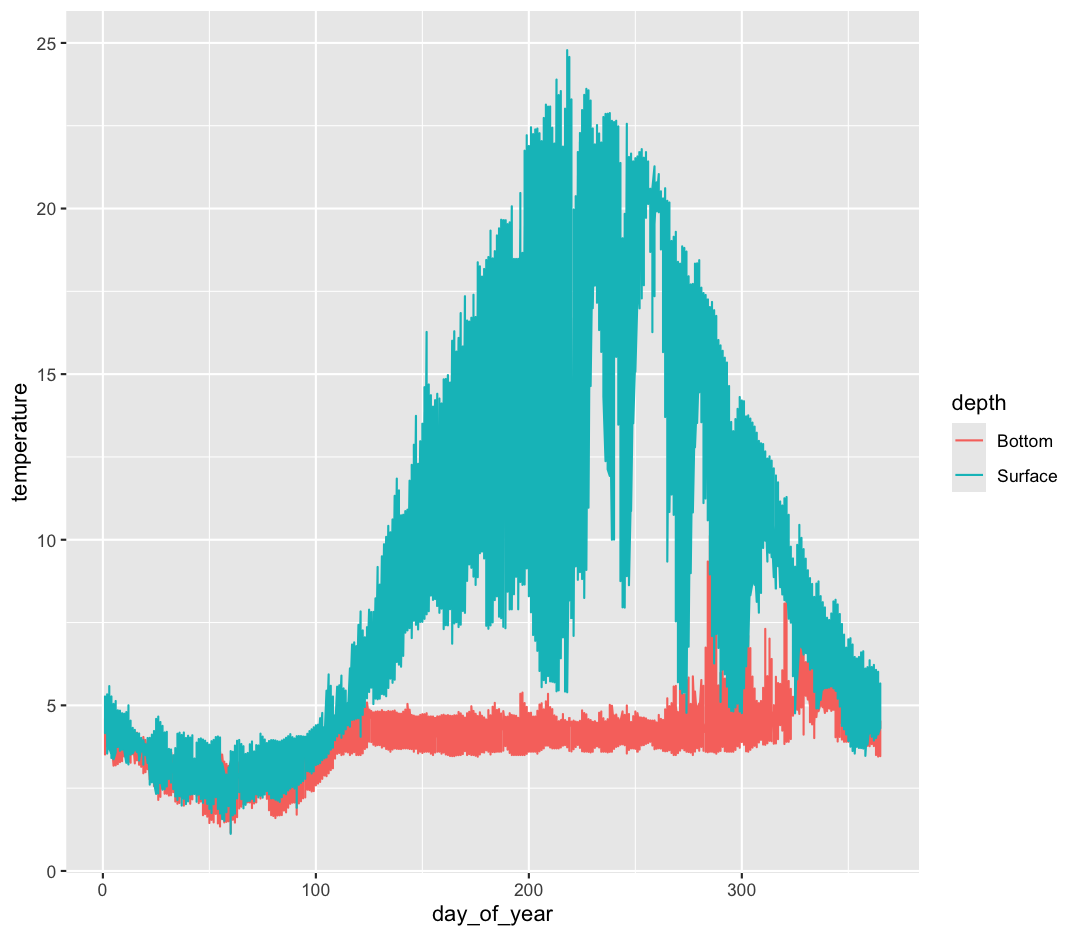
Hmm. This doesn’t look right. By setting the color value, we got a line for each depth, but the line covers all four buoy locations as well. What we really want is a line for each temperature sensor. We need to tell ggplot that we want to connect the values for each sensor value instead. To do this, we need to use the group= aesthetic.
ggplot(data = buoy_data) +
aes(x = day_of_year, y = temperature, group = sensor, color = depth) +
geom_line()
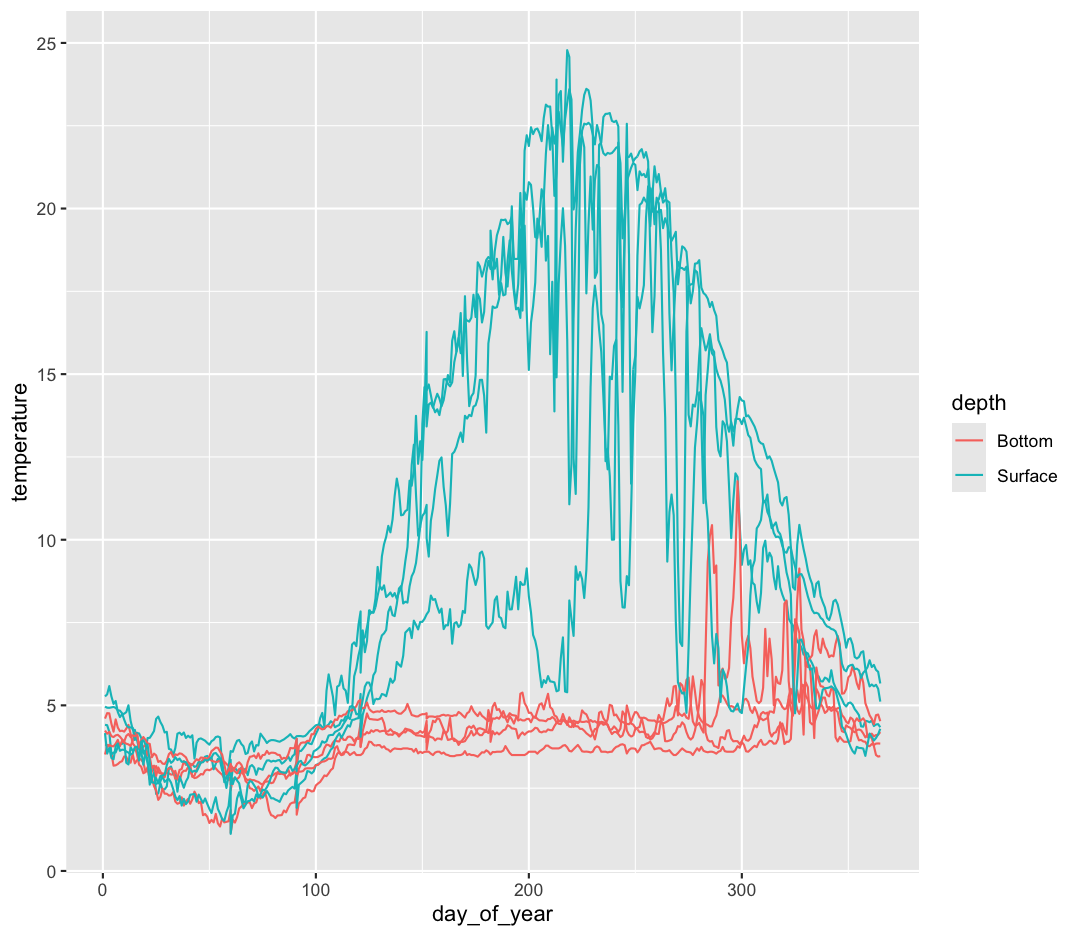
That’s looking much better!
Bonus Exercise: More line plots
Great job making your first line plot! Hmmm – one of the surface sensors warms up much slower compared to the others. What
aesargument can you change to figure out which buoy this comes from?Solution
ggplot(data = buoy_data) + aes(x = day_of_year, y = temperature, group = sensor, color = buoy) + geom_line()
The Toronto buoy warms up much slower compared to the other three buoys.
Facets
The plot we made above does a good job of demonstrating the overall differences between surface and bottom sensors. However, it in some sections it’s difficult to see trends for each buoy because the lines vary so much on top of each other. If you have a lot of different columns to try to plot or have distinguishable subgroups in your data, a powerful plotting technique called faceting might come in handy. When you facet your plot, you basically make a bunch of smaller plots and combine them together into a single image. Luckily, ggplot makes this very easy. Let’s start with our plot from above.
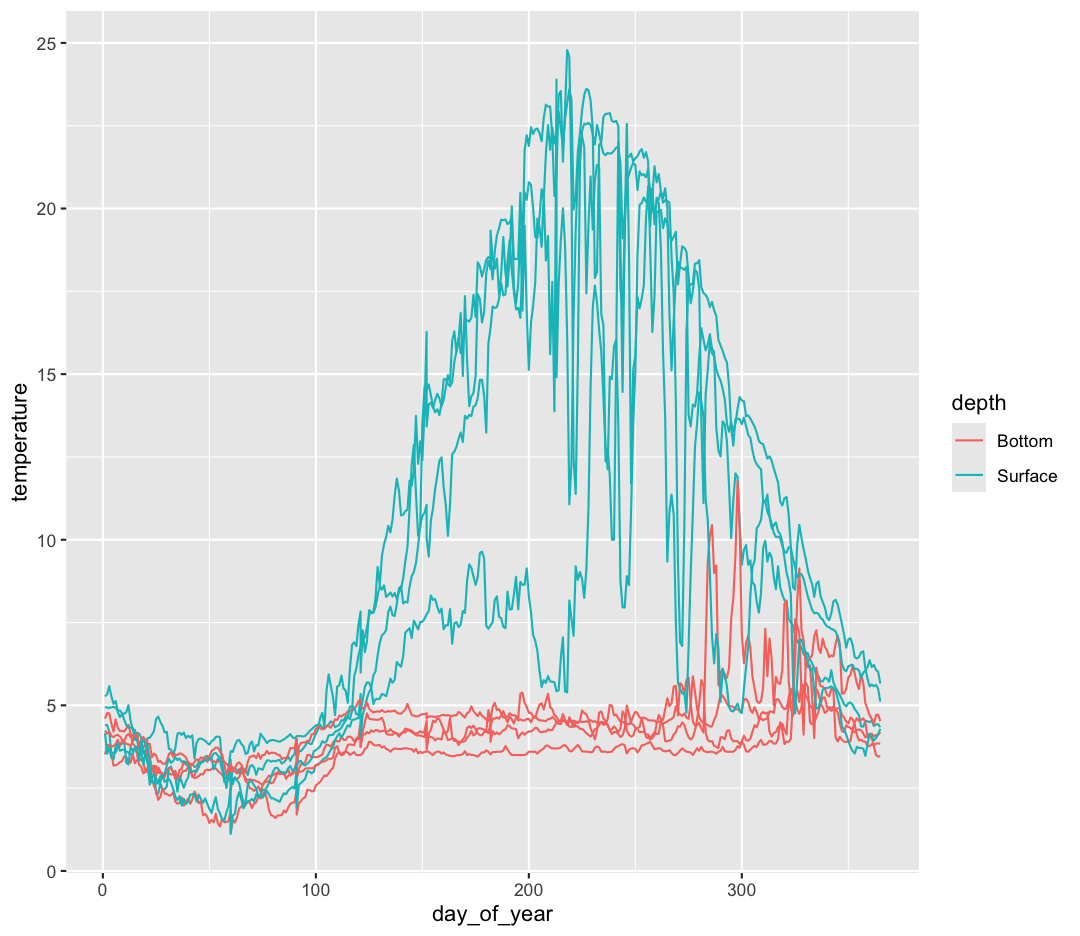
ggplot(data = buoy_data) +
aes(x = day_of_year, y = temperature, group = sensor, color = depth) +
geom_line()
Now, let’s make four separate plots, which correspond to each buoy. We can do this with facet_wrap()
ggplot(data = buoy_data) +
aes(x = day_of_year, y = temperature, group = sensor, color = depth) +
geom_line() +
facet_wrap(~buoy)
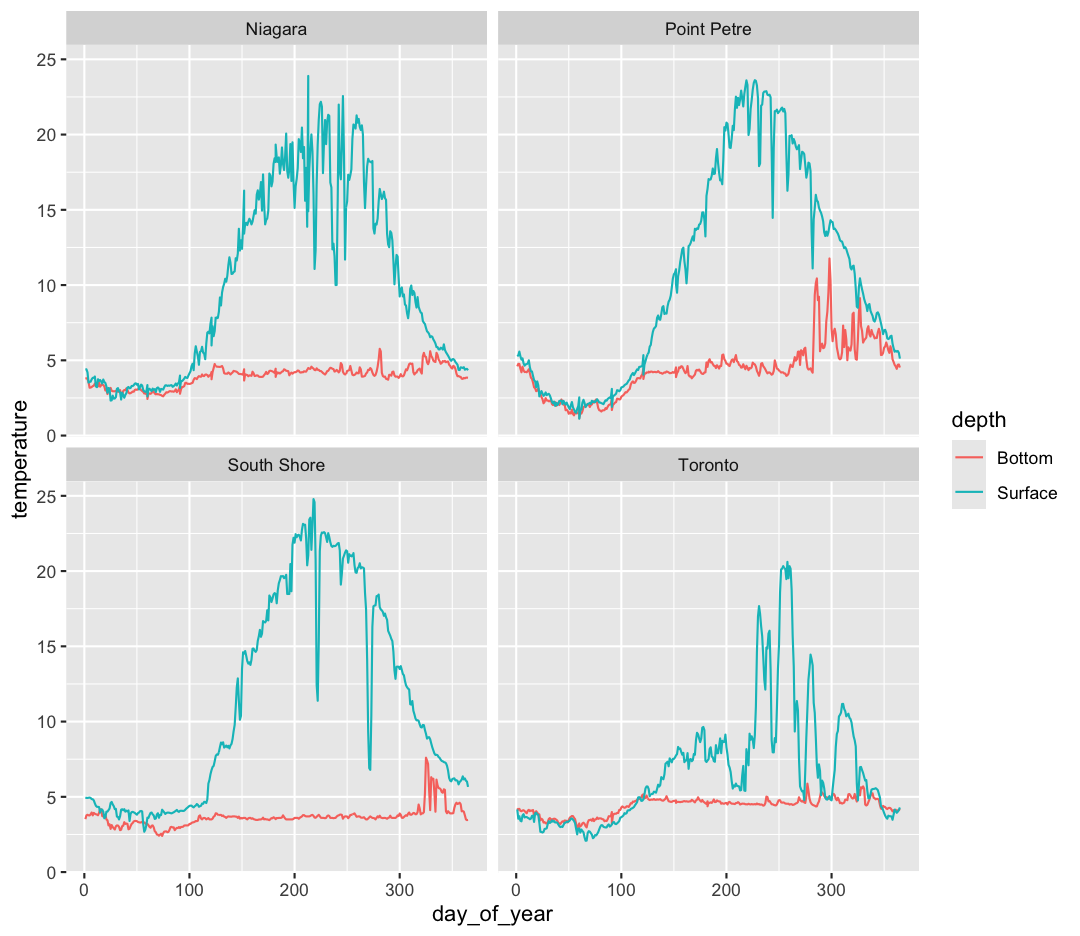
Note that facet_wrap requires this ~ in order to pass in the column names. You can interpret the ~ as “facet by this. We can see in this output that we get a separate box with a label for each buoy so that only the lines for the buoy are in that box. Now it is much easier to see trends in our data! We see that while surface waters are often much warmer than bottom waters, there can be sudden drops in temperature. As limnologists (people who study lakes), we call these “upwellings”. Through our analyses, we can see these upwellings are more common near Toronto than near Niagara!
Bonus Exercise: Free axes on faceted plots
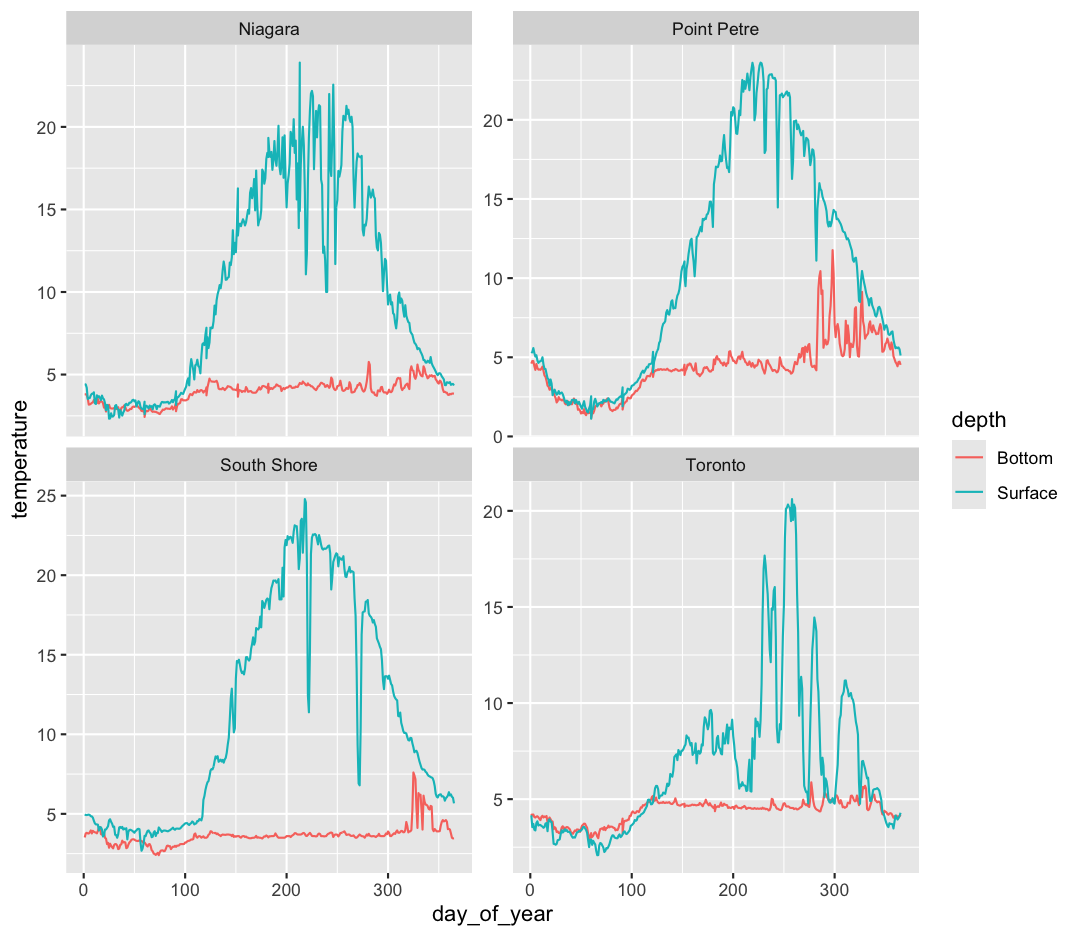
Often, the range of values between facets is very different; for example, Toronto’s max temperature is five degrees less than the South Shore station. Perhaps we want to emphasise the trends within each group, with less concern about comparing values between facets. We can modify the range of facet axes by adding the argument
scales =inside ourfacet_wrapcommand.Example solution
ggplot(data = buoy_data) + aes(x = day_of_year, y = temperature, group = sensor, color = depth) + geom_line() + facet_wrap(~buoy, scales = "free_y")
The other faceting function ggplot provides is facet_grid(). The main difference is that facet_grid() will make sure all of your smaller boxes share a common axis. In this example, we will stack all the boxes on top of each other into rows so that their x axes all line up.
ggplot(data = buoy_data) +
aes(x = day_of_year, y = temperature, group = sensor, color = depth) +
geom_line() +
facet_grid(rows = vars(buoy))
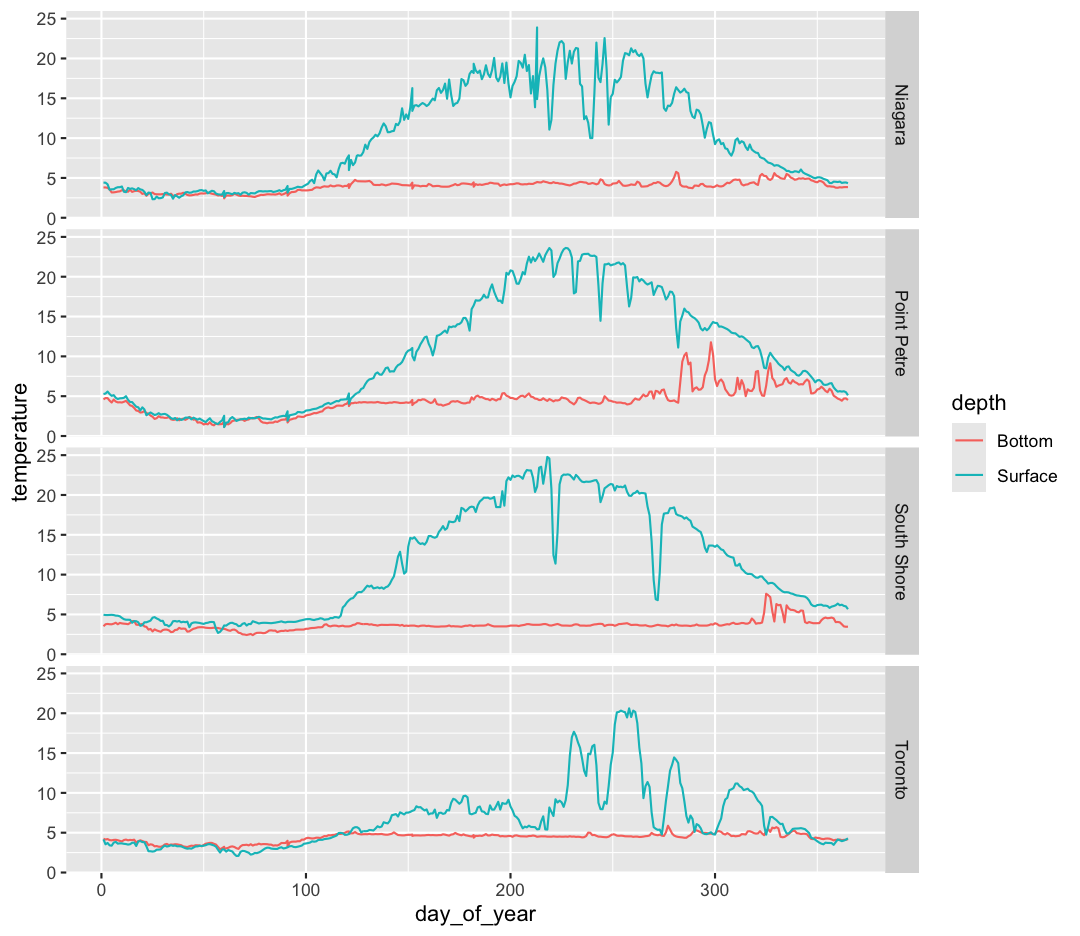
Unlike the facet_wrap output where each box got its own x and y axis, with facet_grid(), there is only one x axis along the bottom. We also used the function vars() to make it clear we’re referencing the column buoy.
Discrete Plots
So far we’ve looked at two plot types (geom_point and geom_line) which work when both the x and y values are numeric. But sometimes you may have one of your values be discrete (a factor or character).
We are going to return to our sample_data dataframe to practice some new plot types. We’ve previously used the discrete values of the env_group column to color in our points. But now let’s try moving that variable to the x axis. Let’s say we are curious about comparing the distribution of the cell abundance values for each of the different env_groups. We can do so using a box plot. Try this out yourself in the exercise below!
Box plots
Using the
sample_datadata, use ggplot to create a box plot with env_group on the x axis and cells_per_ml on the y axis. You can use the examples from earlier in the lesson as a template to remember how to pass ggplot data and map aesthetics and geometries onto the plot. If you’re really stuck, feel free to use the internet as well!Solution
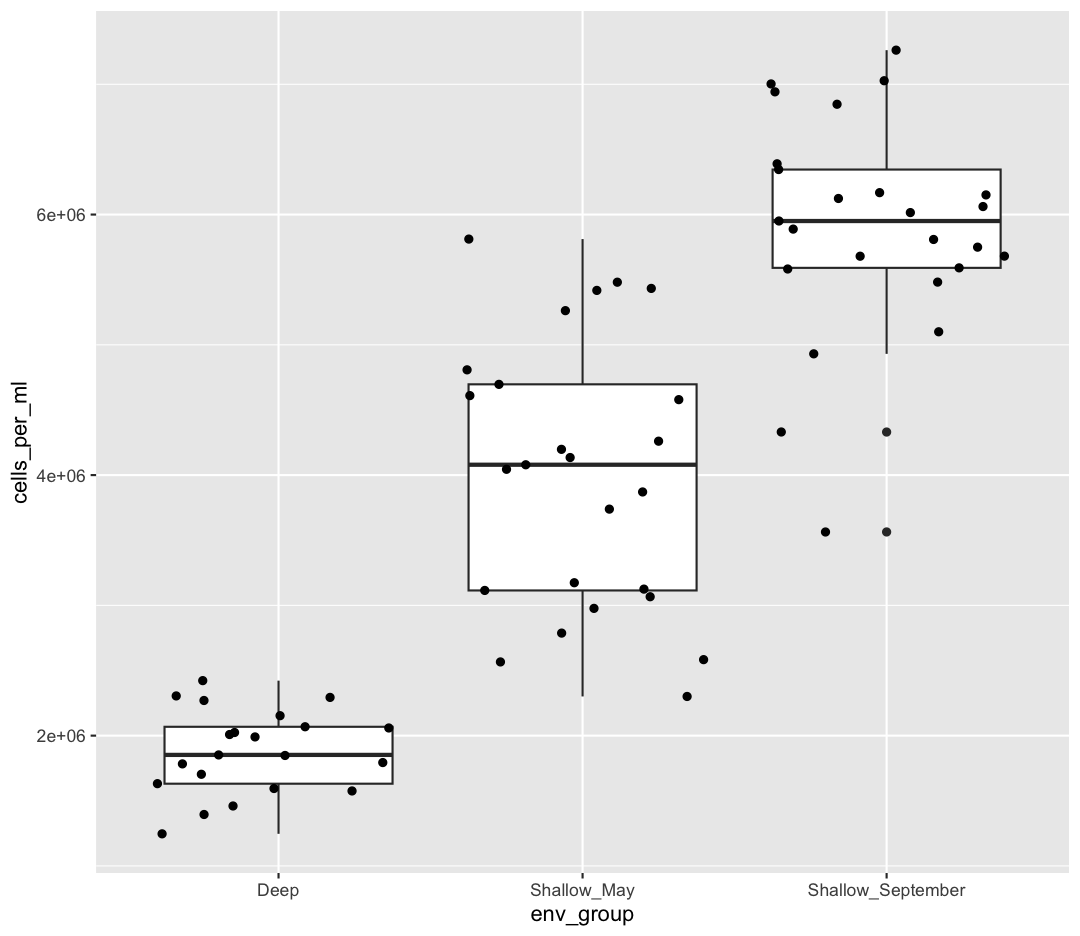
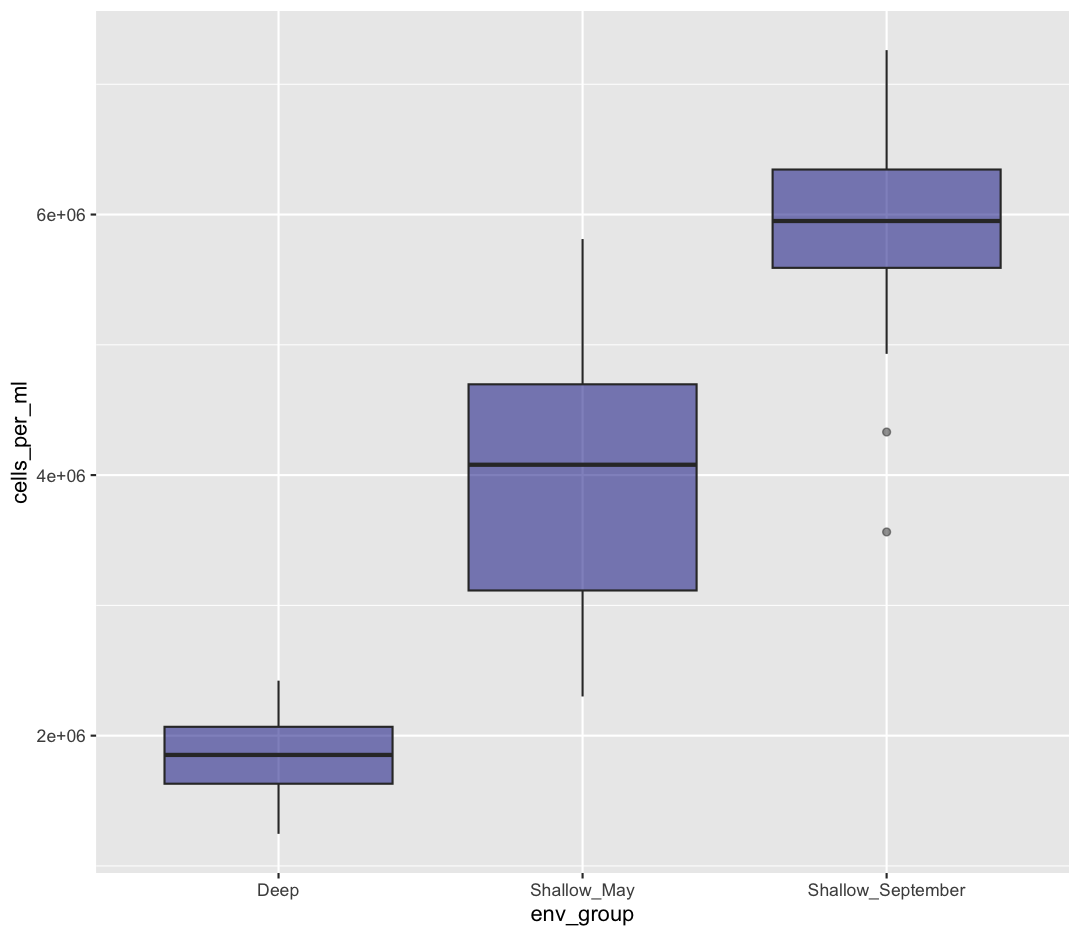
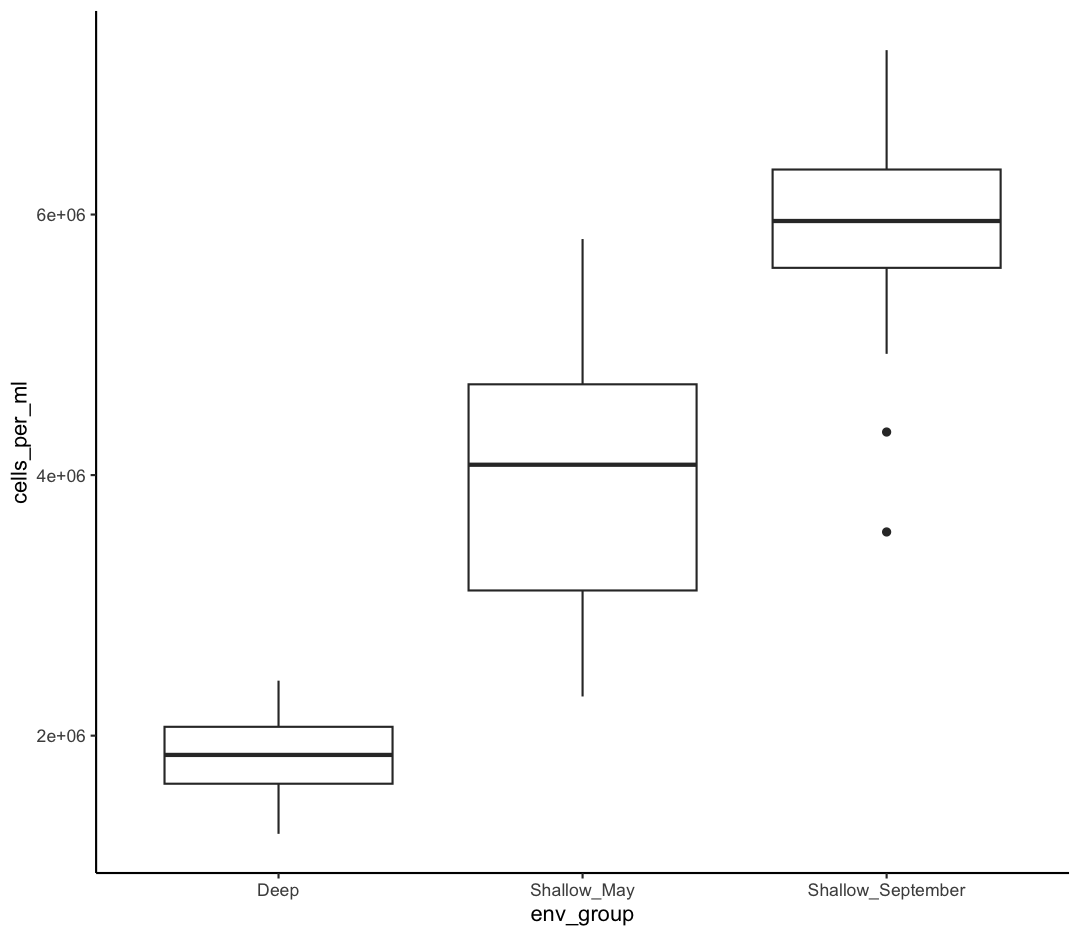
ggplot(data = sample_data) + aes(x = env_group, y = cells_per_ml) + geom_boxplot()
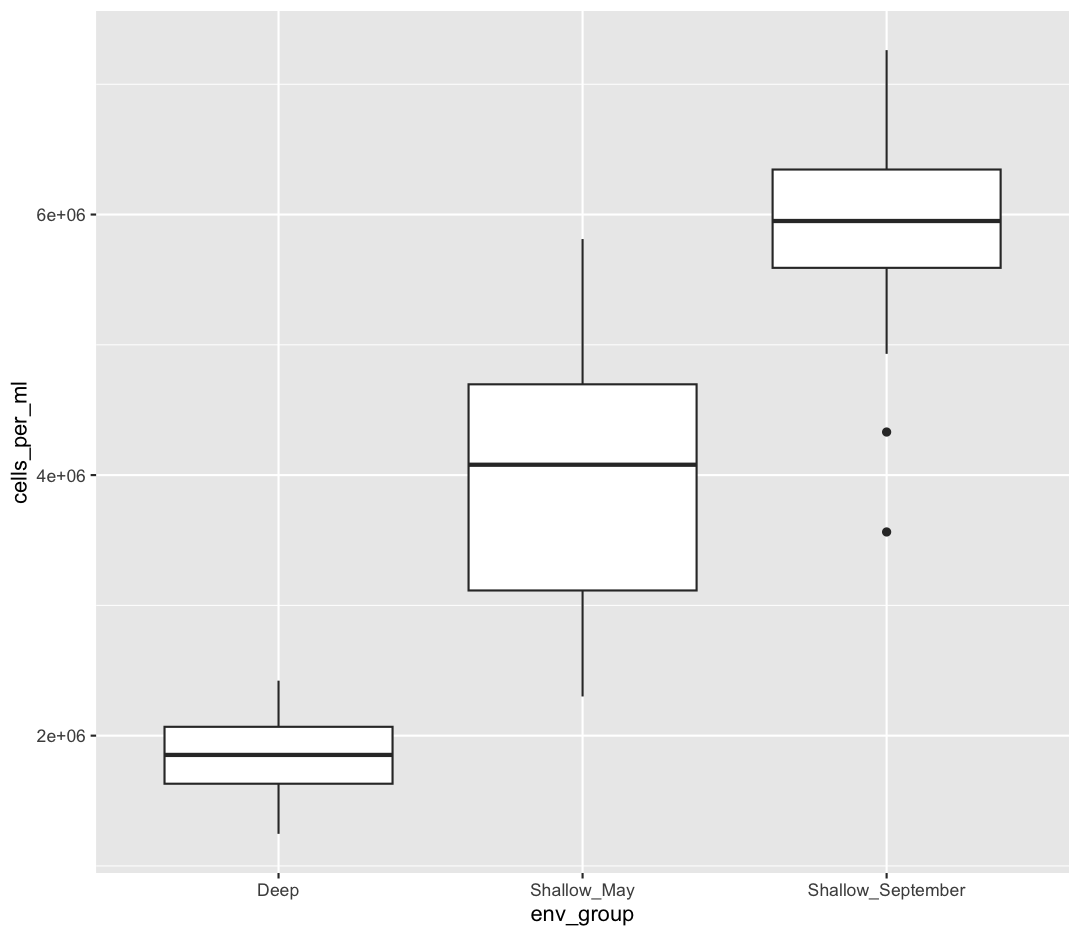
This type of visualization makes it easy to compare the range and spread of values across groups. The “middle” 50% of the data is located inside the box and outliers that are far away from the central mass of the data are drawn as points.
Bonus Exercise: Other discrete geoms
Take a look a the ggplot “data visualization” cheat sheet. Find all the geoms listed under “one discrete, one continuous”. Try replacing
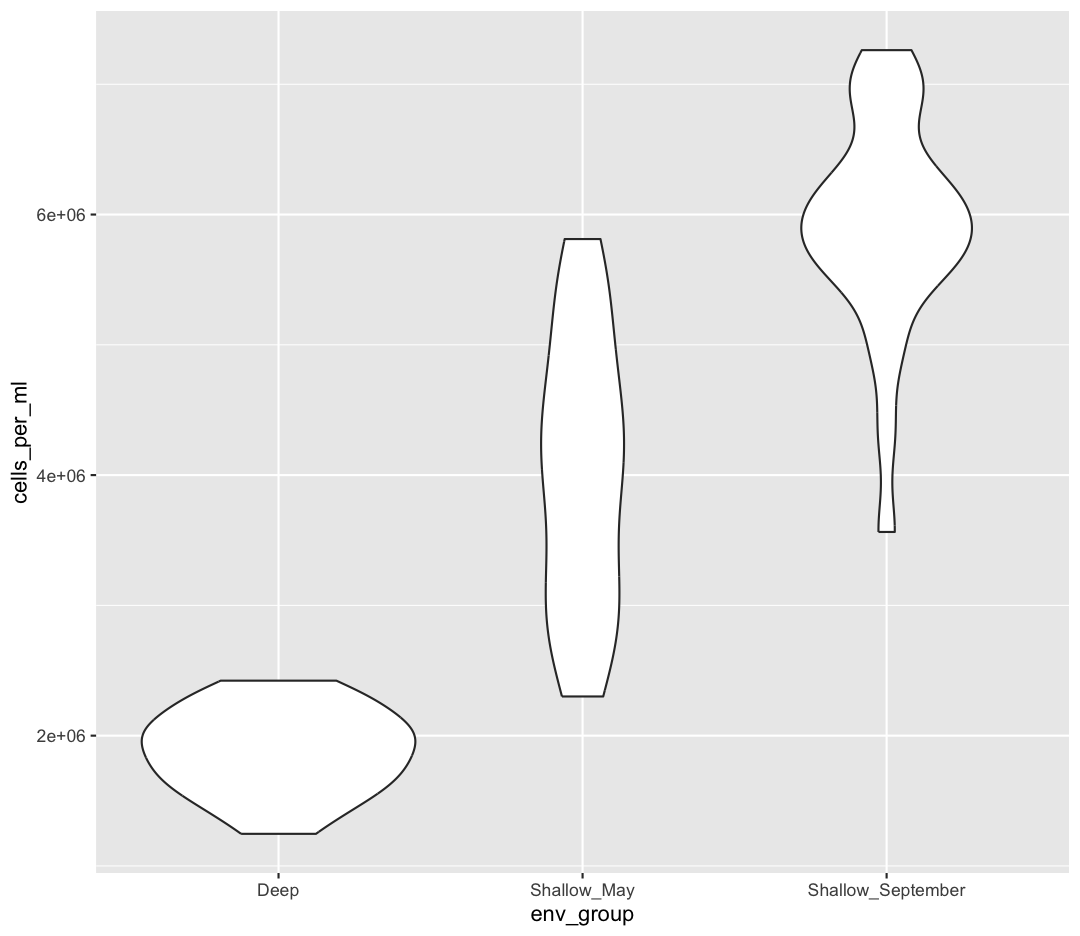
geom_boxplotwith one of these other functions.Example solution
ggplot(data = sample_data) + aes(x = env_group, y = cells_per_ml) + geom_violin()
Layers
So far we’ve only been adding one geom to each plot, but each plot object can actually contain multiple layers and each layer has it’s own geom. Let’s start with a basic boxplot:
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot()
Box plots are a great way to see the overall spread of your data. However, it is good practice to also give your reader as sense of how many observations have gone into your boxplots. To do so, we can plot each observation as an individual point, on top of the boxplot.
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot() +
geom_point()
OK, we’ve drawn the points but most of them stack up on top of each other. One way to make it easier to see all the data is to “jitter” the points, or move them around randomly so they don’t stack up on top of each other. To do this, we use geom_jitter rather than geom_point
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot() +
geom_jitter()
Be aware that these movements are random so your plot will look a bit different each time you run it!
Now let’s try switching the order of geom_boxplot and geom_jitter. What happens? Why?
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_jitter() +
geom_boxplot()
Since we plot the geom_jitter layer first, the boxplot layer is placed on top of the geom_jitter layer, so we cannot see most of the points.
Note that each layer can have it’s own set of aesthetic mappings. So far we’ve been using aes() outside of the other functions. When we do this, we are setting the “default” aesthetic mappings for the plot. We could do the same thing by passing the values to the ggplot() function call as is sometimes more common:
ggplot(data = sample_data, mapping = aes(x = env_group, y = cells_per_ml)) +
geom_boxplot() +
geom_jitter()
However, we can also use aesthetic values for only one layer of our plot. To do that, you an place an additional aes() inside of that layer. For example, what if we want to change the size for the points so they are scaled by chlorophyll, but we don’t want to change the box plot? We can do:
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot() +
geom_jitter(aes(size = chlorophyll))
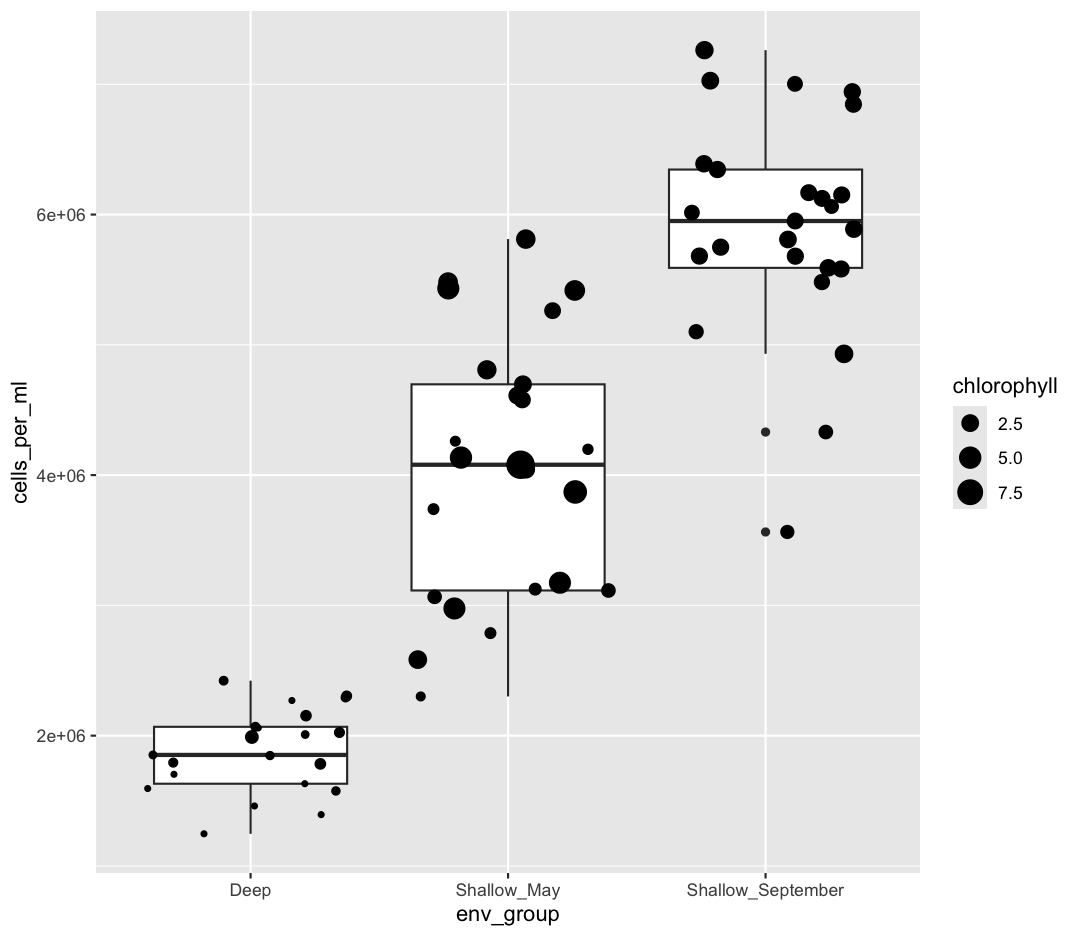
Both geom_boxplot and geom_jitter will inherit the default values of aes(env_group, cells_per_ml) but only geom_jitter will also use aes(size = chlorophyll).
Functions within functions
In the two examples above, we placed the
aes()function inside another function – see how in the line of codegeom_jitter(aes(size = chlorophyll)),aes()is nested insidegeom_jitter()? When this happens, R evaluates the inner function first, then passes the output of that function as an argument to the outer function.Take a look at this simpler example. Suppose we have:
sum(2, max(6,8))First R calculates the maximum of the numbers 6 and 8 and returns the value 8. It passes the output 8 into the sum function and evaluates:
sum(2, 8)[1] 10
Color vs. Fill
Let’s say we want to spice up our plot a bit by adding some color. Maybe we want our boxplot to have a fancy color like “pink.” We can do this by explicitly setting the color aesthetic inside the geom_boxplot function. Note that because we are assigning a color directly and not using any values from our data to do so, we do not need to use the aes() mapping function. Let’s try it out:
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(color="pink")
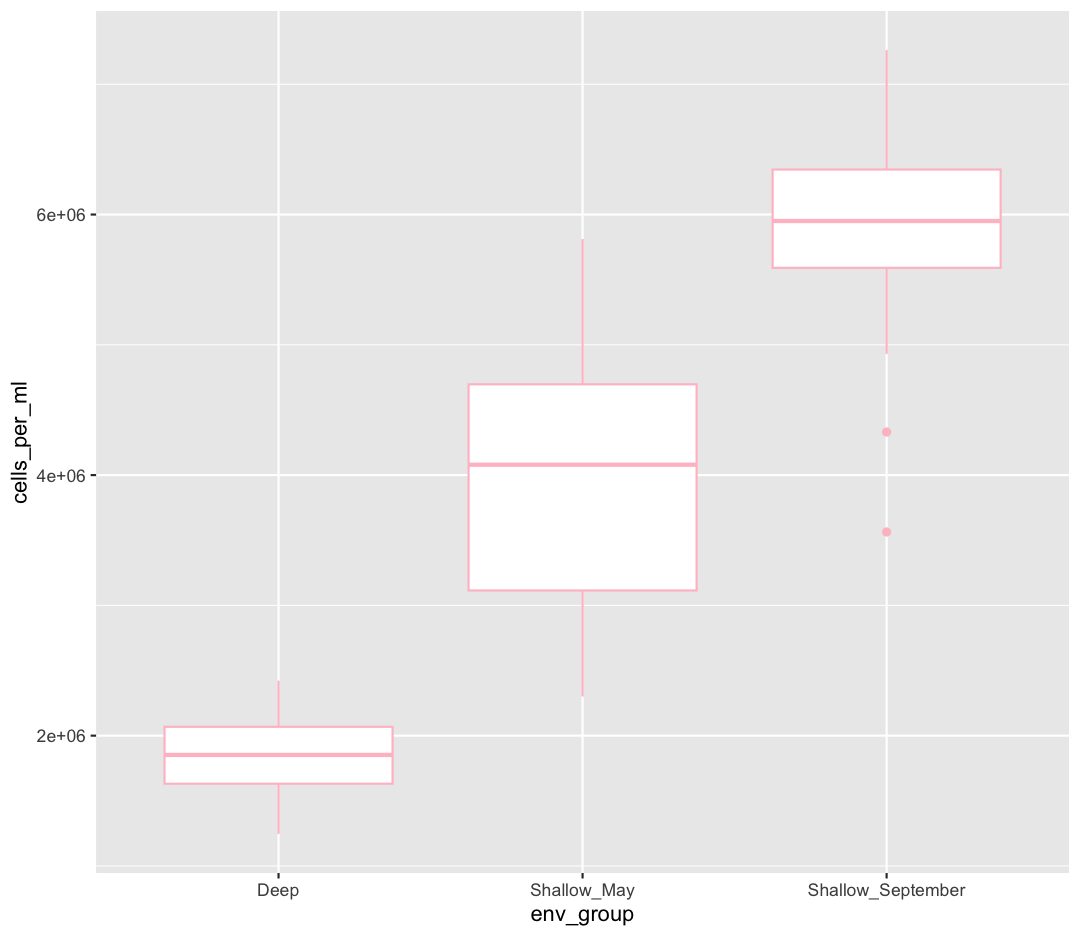
Well, that didn’t get all that colorful. That’s because objects like these boxplots have two different parts that have a color: the shape outline, and the inner part of the shape. For geoms that have an inner part, you change the fill color with fill= rather than color=, so let’s try that instead
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(fill="pink")
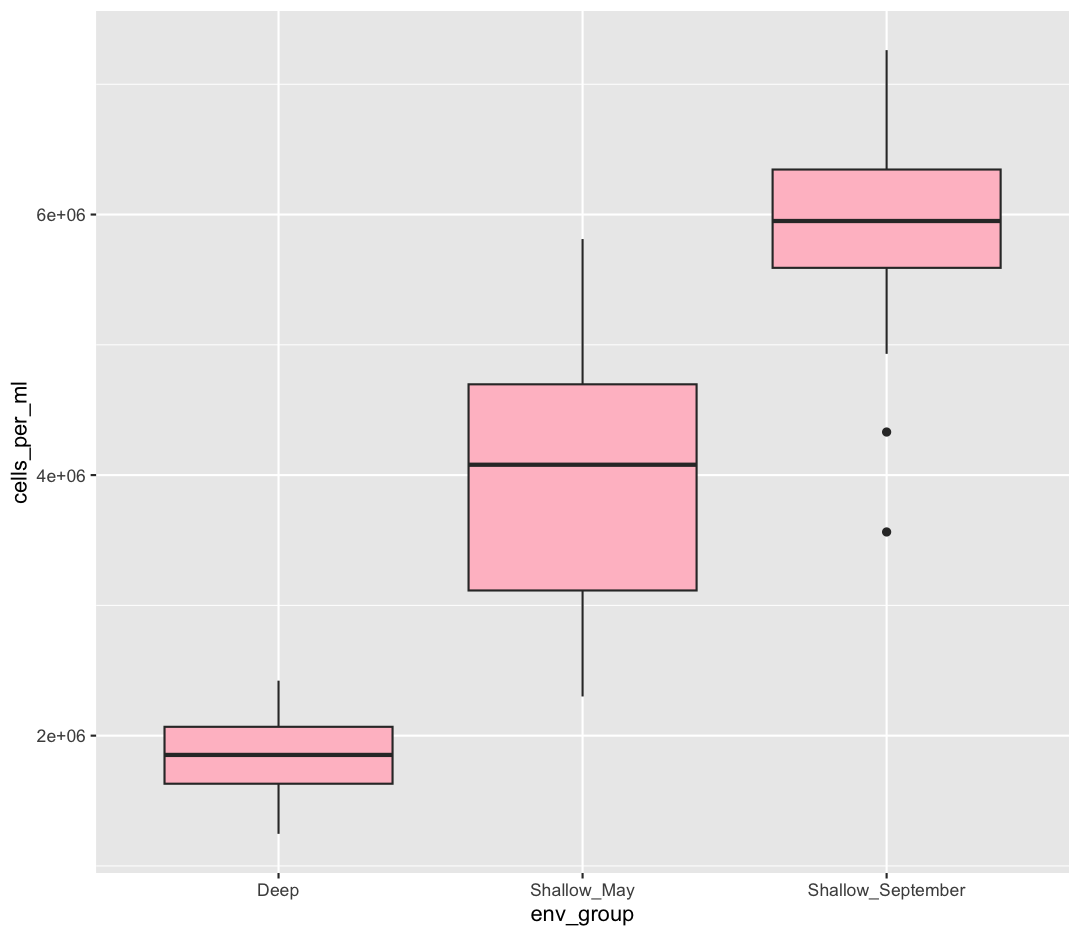
That’s some plot now isn’t it! So “pink” maybe wasn’t the prettiest color. R knows lots of color names. You can see the full list if you run colors() in the console. Since there are so many, you can randomly choose 10 if you run sample(colors(), size = 10).
choosing a color
Use
sample(colors(), size = 10)a few times until you get an interesting sounding color name and swap that out for “pink” in the violin plot example.
We could also use a variable to determine the fill. Compare this to what you see when you map the fill property to your data rather than setting a specific value.
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(aes(fill=env_group))
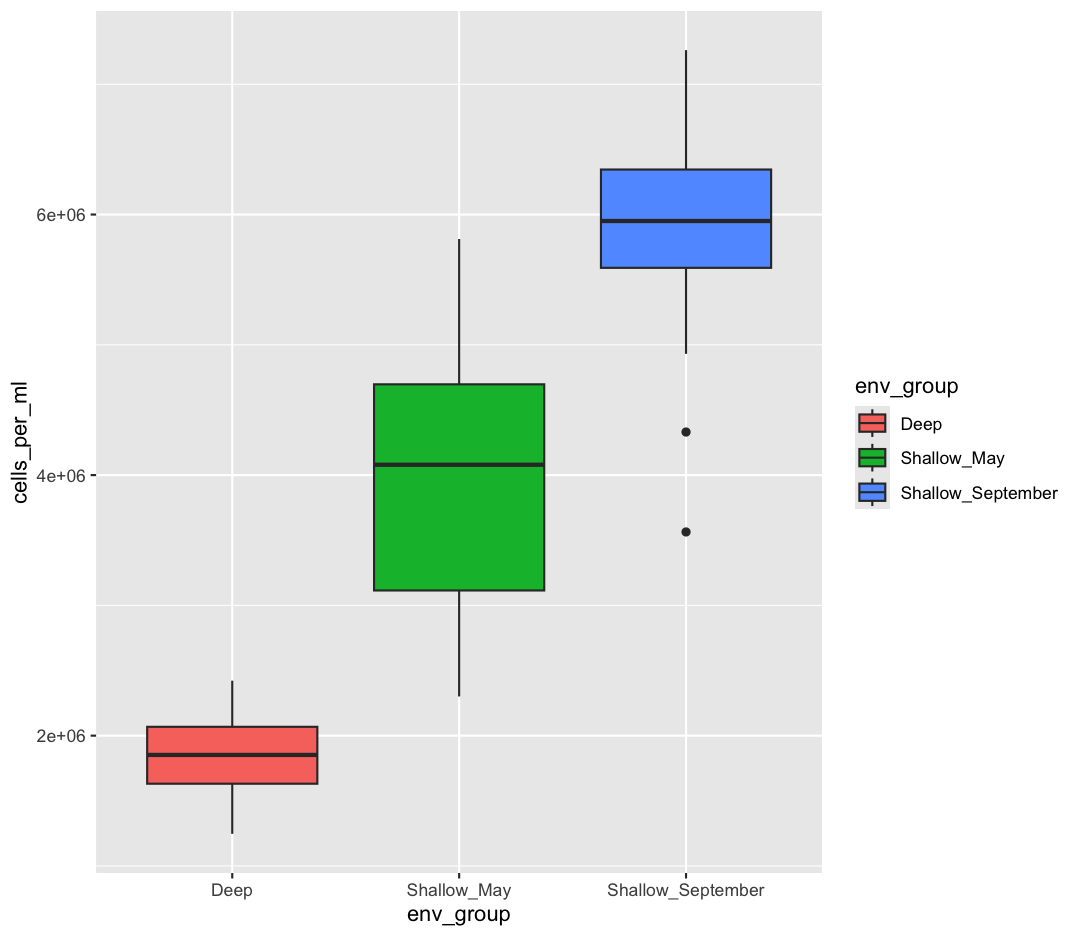
But what if we want to specify specific colors for our plots? The colors that
ggplot uses are determined by the color “scale”. Each aesthetic value we can
supply (x, y, color, etc) has a corresponding scale. Let’s change the colors to
make them a bit prettier. We can do that by using the function scale_fill_manual
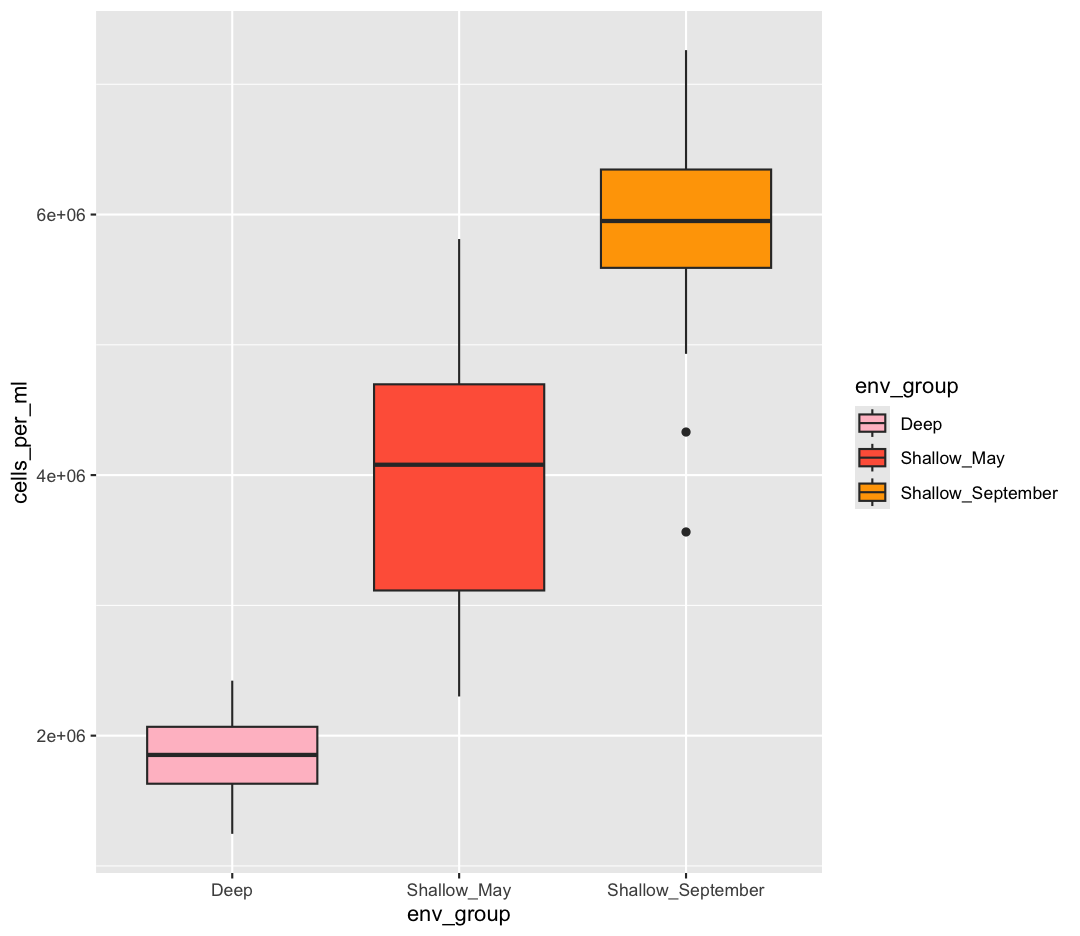
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(aes(fill=env_group)) +
scale_fill_manual(values = c("pink", "tomato","orange1"))
Sometimes manually choosing colors is frustrating. There are many packages which produce pre-made palettes which you can supply to your data. A common one is RColorBrewer. We can use the palettes from RColorBrewer using the scale_color_brewer function.
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(aes(fill=env_group)) +
scale_fill_brewer(palette = "Set1")
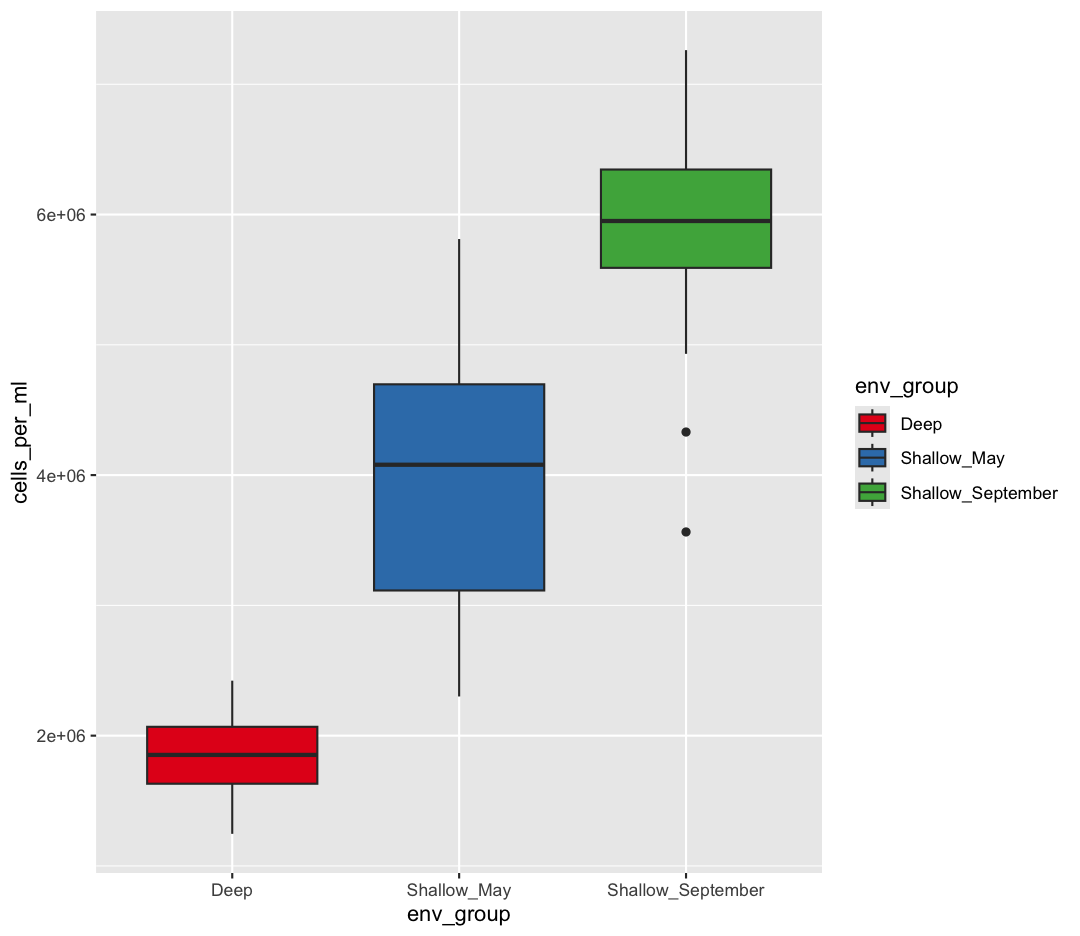
The scale_color_brewer() function is just one of many you can use to change
colors. There are bunch of “palettes” that are built-in. You can view them all
by running RColorBrewer::display.brewer.all() or check out the Color Brewer
website for more info about choosing plot colors.
There are also lots of other fun options:
Bonus Exercise: Lots of different palettes!
Play around with different color palettes. Feel free to install another package and choose one of those if you want. Pick your favorite!
Solution
You can use RColorBrewer::display.brewer.all() to pick a color palette. As a bonus, you can also use one of the packages listed above. Here’s an example:
#install.packages("wesanderson") # install package library(wesanderson) ggplot(data = sample_data) + aes(x = temperature) + labs(x = "Temperature (C)") + aes(y = cells_per_ml) + labs(y = "Cells per mL") + geom_point() + labs(title = "Does temperature affect microbial abundance?") + aes(color = env_group) + scale_color_manual(values = wes_palette('Cavalcanti1'))
Bonus Exercise: Transparency
Another aesthetic that can be changed is how transparent our colors/fills are. The
alphaparameter decides how transparent to make the colors. By default,alpha = 1, and our colors are completely opaque. Decreasingalphaincreases the transparency of our colors/fills. Try changing the transparency of our boxplot. (Hint: Should alpha be inside or outsideaes()?)Solution
ggplot(data = sample_data) + aes(x = env_group, y = cells_per_ml) + geom_boxplot(fill="darkblue", alpha = 0.5)
Changing colors
What happens if you run:
ggplot(data = sample_data) + aes(x = env_group, y = cells_per_ml) + geom_boxplot(aes(fill = "springgreen"))
Why doesn’t this work? How can you fix it? Where does that color come from?
Solution
In this example, you placed the fill inside the
aes()function. Because you are using an aesthetic mapping, the “scale” for the fill will assign colors to values - in this case, you only have one value: the word “springgreen.” Instead, trygeom_boxplot(fill = "springgreen").
Univariate Plots
We jumped right into making plots using multiple variables. But what if we wanted to take a look at just one column? In that case, we only need to specify a mapping for x and choose an appropriate geom. Let’s start with a histogram to see the range and spread of the cell abundance values
ggplot(sample_data) +
aes(x = cells_per_ml) +
geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
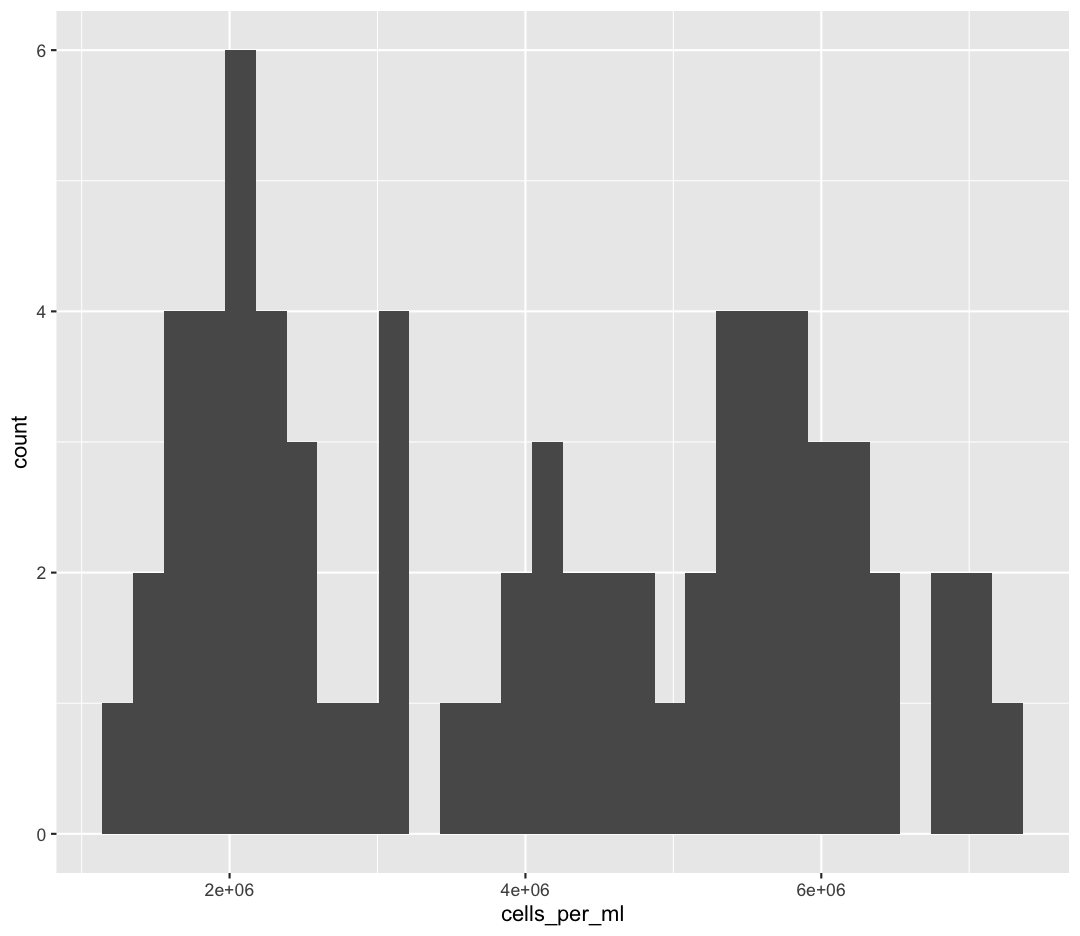
You should not only see the plot in the plot window, but also a message telling you to choose a better bin value. Histograms can look very different depending on the number of bars you decide to draw. The default is 30. Let’s try setting a different value by explicitly passing a bin= argument to the geom_histogram later.
ggplot(sample_data) +
aes(x = cells_per_ml) +
geom_histogram(bins=10)
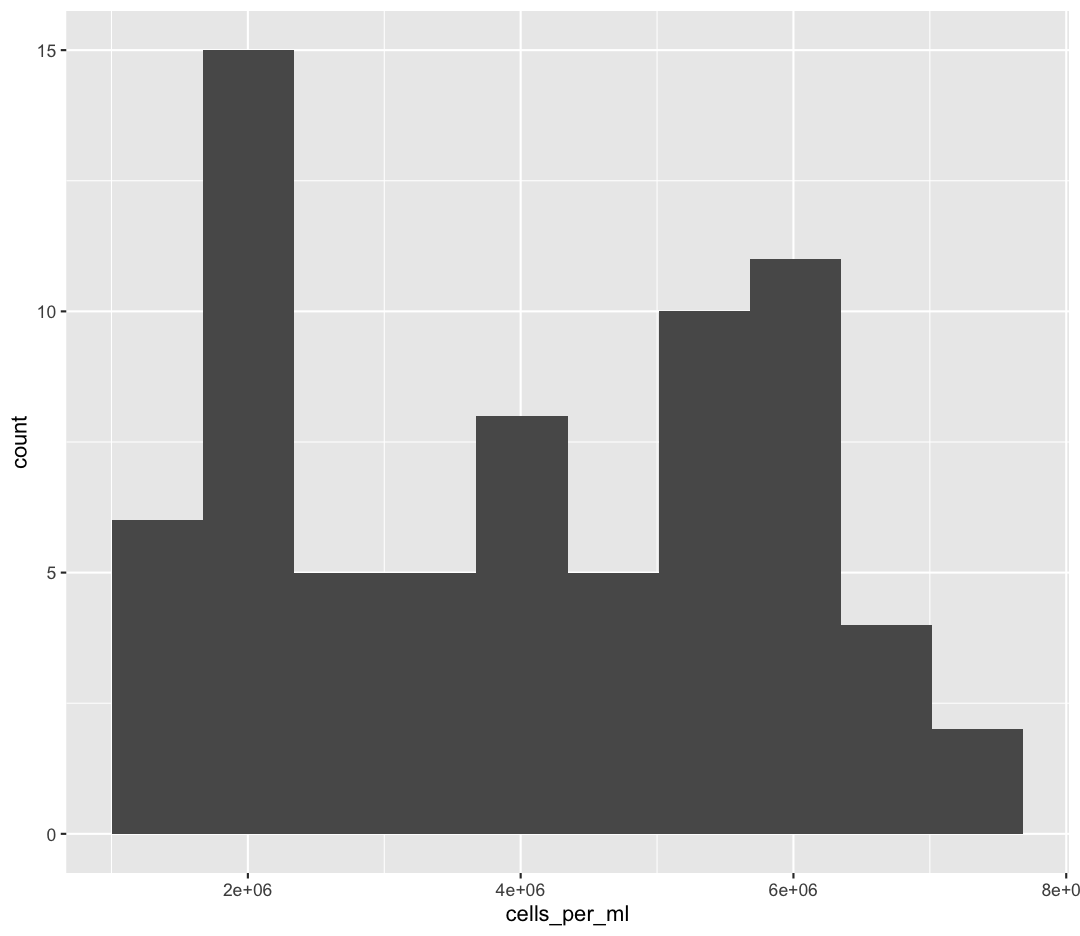
Try different values like 5 or 50 to see how the plot changes.
Bonus Exercise: One variable plots
Rather than a histogram, choose one of the other geometries listed under “One Variable” plots on the ggplot cheat sheet. Note that we used
cells_per_mlhere which has continuous values. If you want to try the discrete options, try mappingenv_groupto x instead.Example solution
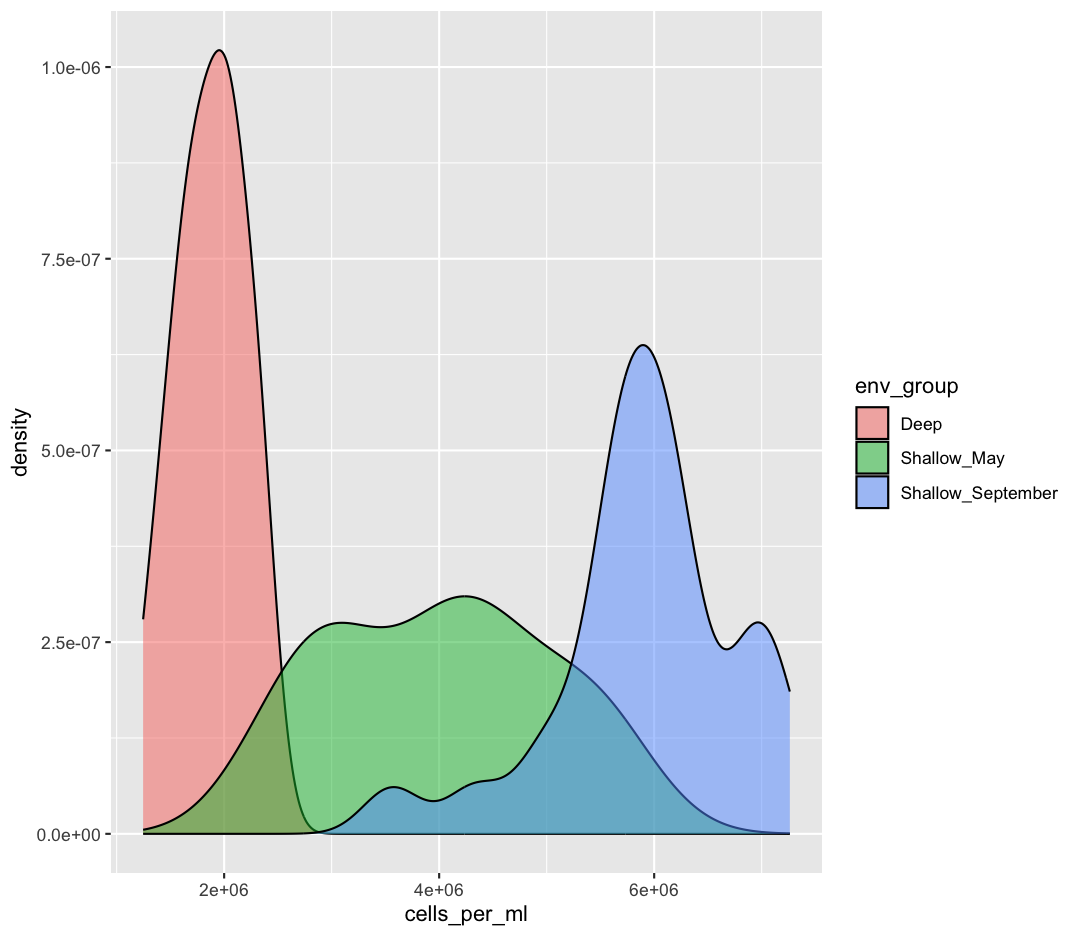
ggplot(sample_data) + aes(x = cells_per_ml) + geom_density()
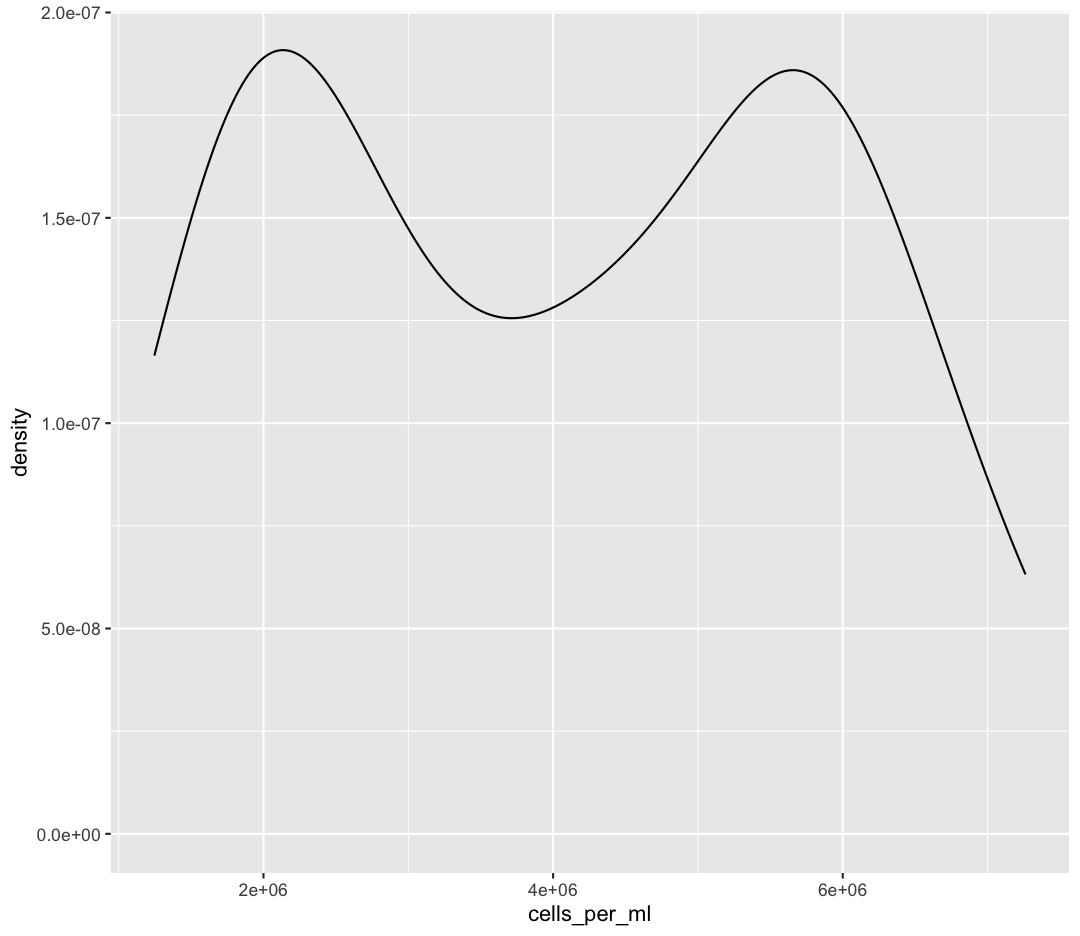
Bonus Exercise: One variable plots with a fill parameter
From our previous work, we know that the distributions of cell abundances are very different between our environmental groups. How can we modulate the
fillparameter of our density plot to show the differences between these groups?Example solution
ggplot(sample_data) + aes(x = cells_per_ml) + geom_density(aes(fill = env_group), alpha = 0.5)
Plot Themes
Our plots are looking pretty nice, but what’s with that grey background? While you can change various elements of a ggplot object manually (background color, grid lines, etc.) the ggplot package also has a bunch of nice built-in themes to change the look of your graph. For example, let’s try adding theme_classic() to our histogram:
ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot() +
theme_classic()
Try out a few other themes, to see which you like: theme_bw(), theme_linedraw(), theme_minimal().
Rotating x axis labels
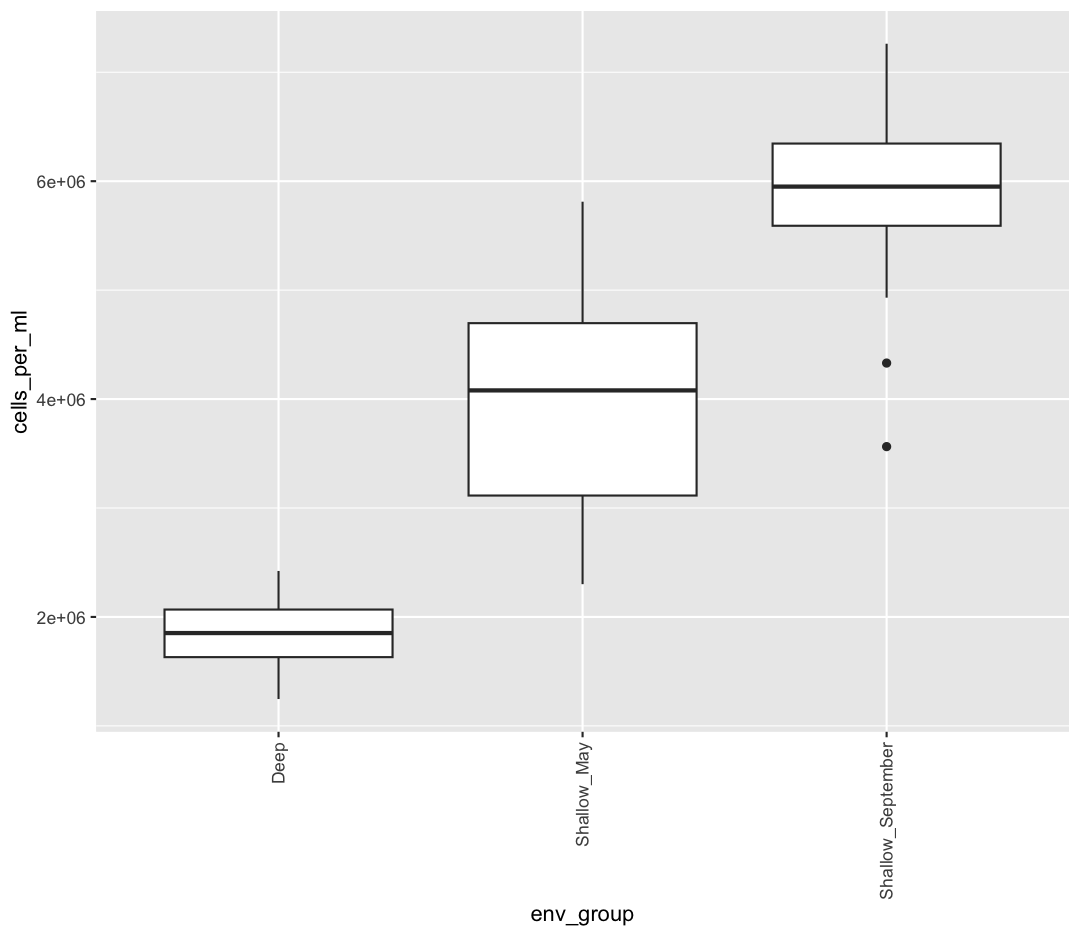
Often, you’ll want to change something about the theme that you don’t know how to do off the top of your head. When this happens, you can do an Internet search to help find what you’re looking for. To practice this, search the Internet to figure out how to rotate the x axis labels 90 degrees. Then try it out using the boxplot we made above.
Solution
ggplot(sample_data) + aes(x = env_group, y = cells_per_ml) + geom_boxplot() + theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
Saving plots
We’ve made a bunch of plots today, but we never talked about how to share them with your friends who aren’t running R! It’s wise to keep all the code you used to draw the plot, but sometimes you need to make a PNG or PDF version of the plot so you can share it with your PI or post it to your Instagram story.
One that’s easy if you are working in RStudio interactively is to use “Export” menu on the Plots tab. Clicking that button gives you three options “Save as Image”, “Save as PDF”, and “Copy To Clipboard”. These options will bring up a window that will let you resize and name the plot however you like.
A better option if you will be running your code as a script from the command line or just need your code to be more reproducible is to use the ggsave() function. When you call this function, it will write the last plot printed to a file in your local directory. It will determine the file type based on the name you provide. So if you call ggsave("plot.png") you’ll get a PNG file or if you call ggsave("plot.pdf") you’ll get a PDF file. By default the size will match the size of the Plots tab. To change that you can also supply width= and height= arguments. By default these values are interpreted as inches. So if you want a wide 4x6 image you could do something like:
ggsave("awesome_plot.jpg", width=6, height=4)
Saving a plot
Try rerunning one of your plots and then saving it using
ggsave(). Find and open the plot to see if it worked!Example solution
ggplot(sample_data) + aes(x = cells_per_ml) + geom_histogram(bins = 20)+ theme_classic()
ggsave("awesome_histogram.jpg", width=6, height=4)Check your current working directory to find the plot!
You also might want to just temporarily save a plot while you’re using R, so that you can come back to it later. Luckily, a plot is just an object, like any other object we’ve been working with! Let’s try storing our boxplot from earlier in an object called box_plot:
box_plot <- ggplot(data = sample_data) +
aes(x = env_group, y = cells_per_ml) +
geom_boxplot(aes(fill=env_group))
Now if we want to see our plot again, we can just run:
box_plot
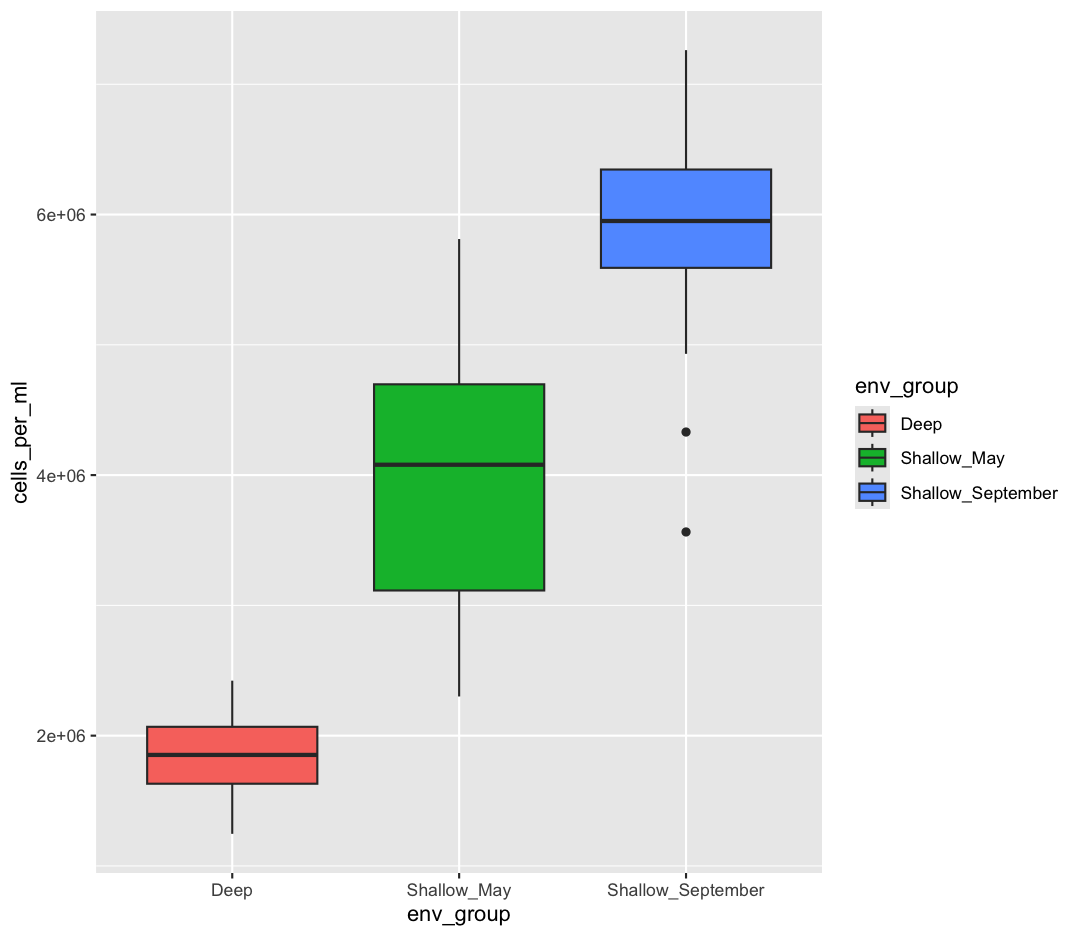
We can also add changes to the plot. Let’s say we want our boxplot to have the black-and-white theme:
box_plot + theme_bw()
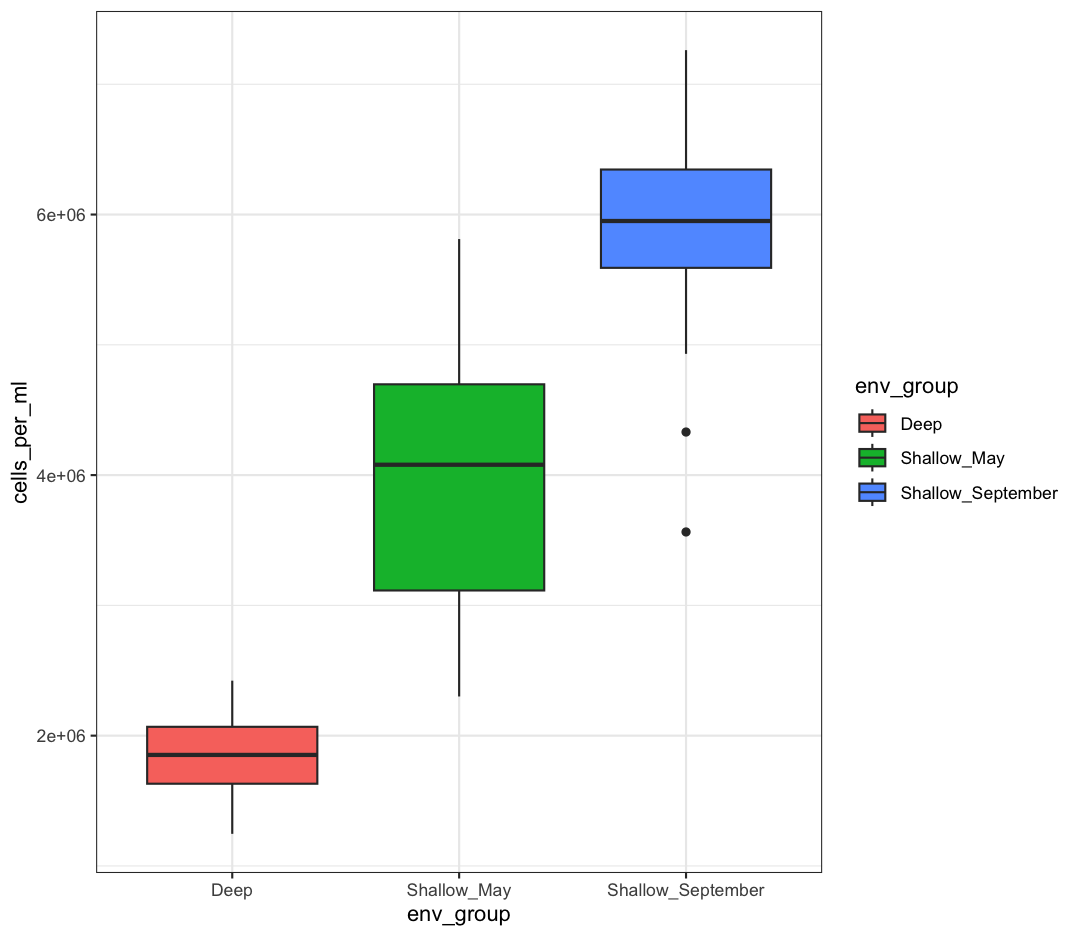
Watch out! Adding the theme does not change the box_plot object! If we want to change the object, we need to store our changes:
box_plot
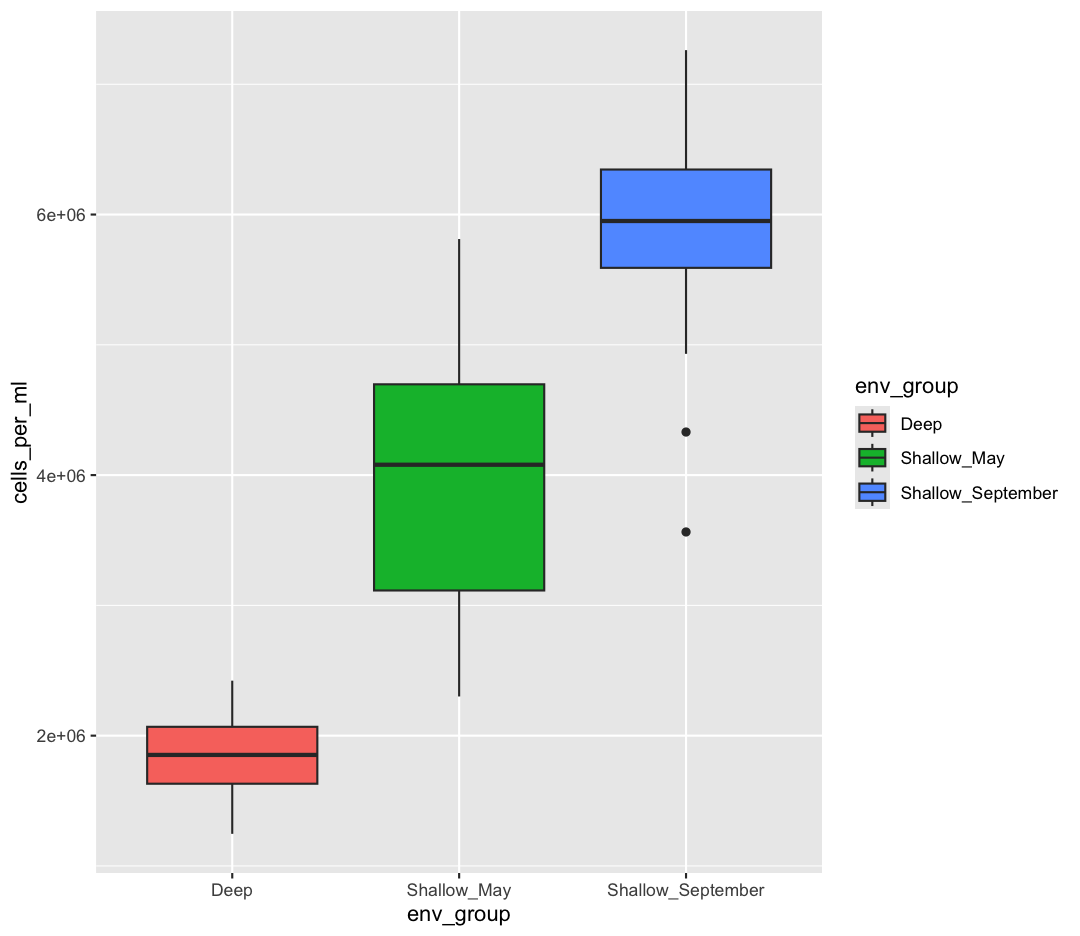
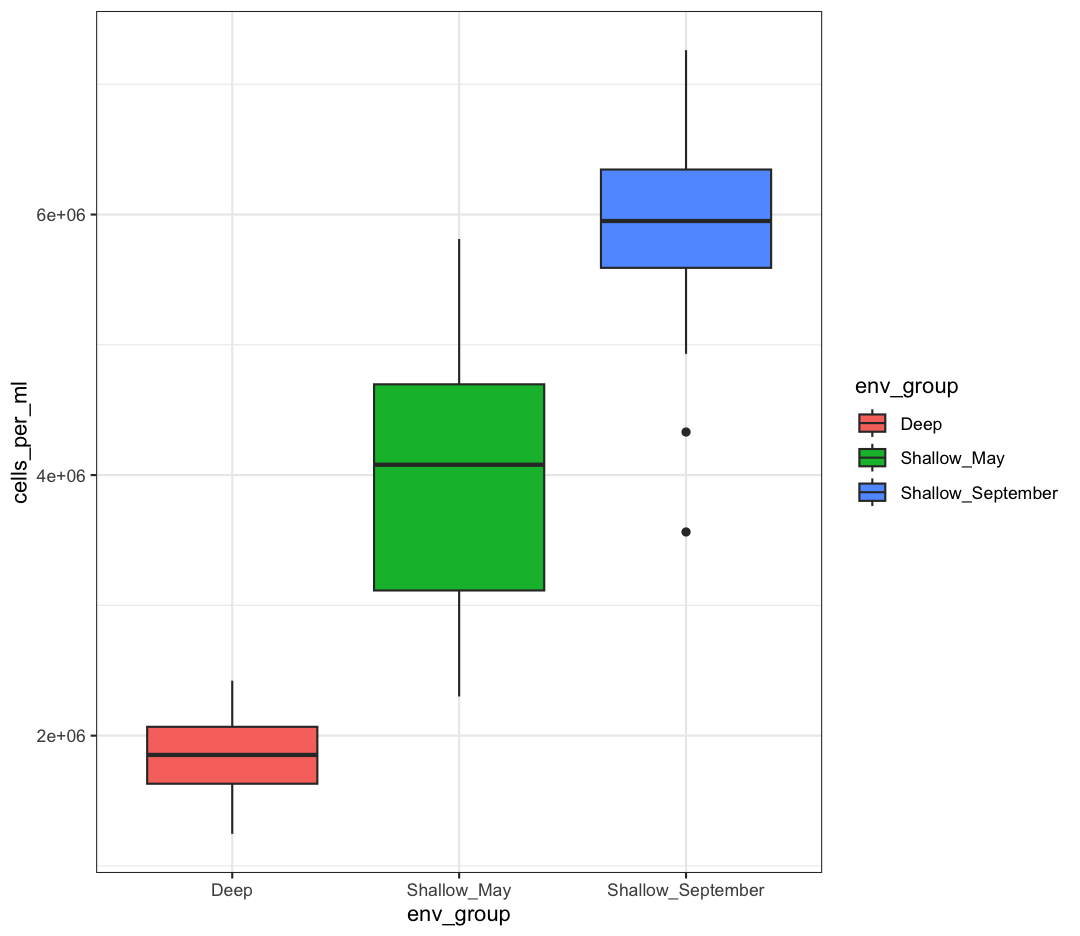
box_plot <- box_plot + theme_bw()
box_plot
We can also save any plot object we have named, even if they were not the plot that we ran most recently. We just have to tell ggsave() which plot we want to save:
ggsave("awesome_box_plot.jpg", plot = box_plot, width=6, height=4)
Bonus Exercise: Create and save a plot
Now try it yourself! Create your own plot using
ggplot(), store it in an object namedmy_plot, and save the plot usingggsave().Example solution
my_plot <- ggplot(data = sample_data)+ aes(x = env_group, y = temperature)+ geom_boxplot(fill = "orange")+ theme_bw()+ labs(x = "env_group", y = "Temperature (C)") ggsave("my_awesome_plot.jpg", plot = my_plot, width=6, height=4)
Glossary of terms
- Aesthetic: a visual property of the objects (geoms) drawn in your plot (like x position, y position, color, size, etc)
- Aesthetic mapping (aes): This is how we connect a visual property of the plot to a column of our data
- Comments: lines of text in our code after a
#that are ignored (not evaluated) by R - Geometry (geom): this describes the things that are actually drawn on the plot (like points or lines)
- Facets: Dividing your data into non-overlapping groups and making a small plot for each subgroup
- Layer: Each ggplot is made up of one or more layers. Each layer contains one geometry and may also contain custom aesthetic mappings and private data
- Factor: a way of storing data to let R know the values are discrete so they get special treatment
Key Points
R is a free programming language used by many for reproducible data analysis.
Geometries are the visual elements drawn on data visualizations (lines, points, etc.), and aesthetics are the visual properties of those geometries (color, position, etc.).
Use
ggplot()and geoms to create data visualizations, and save them usingggsave().